大家好,我是小米!今天我想和大家聊一聊一個經典的Redis問題:緩存雪崩。對于許多互聯網應用來說,緩存是不可或缺的一部分,它能大大提高系統的性能。但是,如果不加以適當管理,緩存問題也可能導致整個系統的崩潰。緩存雪崩就是其中之一。下面讓我們一起來了解一下什麽是緩存雪崩,以及如何有效解決這個問題。
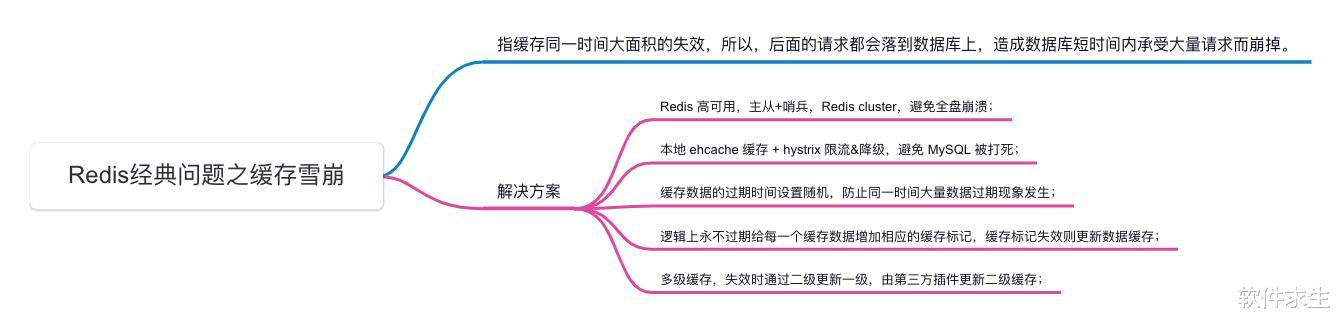
什麽是緩存雪崩?緩存雪崩是指同一時間大面積的緩存失效,從而導致大量請求直接落到數據庫上,造成數據庫在短時間內承受大量請求,進而可能導致數據庫崩潰。通常,緩存雪崩可能由以下情況引起:
緩存統一過期:當大量緩存設置了相同的過期時間,且沒有加以控制時,這些緩存會同時失效,導致大量請求直接訪問數據庫。
單點故障:如果Redis服務器出現故障,所有緩存都無法訪問,這也會導致請求直接落到數據庫上。
系統壓力:系統承受的壓力過大,導致緩存服務器崩潰,導致緩存失效。
那麽,如何解決緩存雪崩問題呢?我爲大家總結了一些有效的解決方案,希望能對大家有所幫助。
Redis高可用:主從複制 + 哨兵機制主從複制:通過將數據複制到多個從服務器,可以確保在主服務器出現問題時,從服務器繼續提供服務。這樣,數據的可用性和冗余性得以提高,避免單點故障導致的緩存雪崩。
哨兵機制:Redis的哨兵機制負責監控Redis主從服務器的健康狀態。一旦主服務器出現問題,哨兵將自動切換到備份服務器作爲新的主服務器,從而保障數據的持續可用。
本地ehcache緩存 + Hystrix限流&降級本地ehcache緩存:通過在應用程序中使用本地緩存(如ehcache)來緩存熱點數據,可以緩解Redis服務器的壓力。當Redis緩存失效時,本地緩存能夠快速提供備份數據,減少對數據庫的直接壓力。
Hystrix限流&降級:Hystrix可以對請求進行動態監控和管理,通過限流、熔斷和降級等機制,確保系統在高壓力下仍然能穩定運行,防止數據庫過載。
緩存數據的過期時間設置隨機隨機過期時間:爲每一個緩存數據設置不同的過期時間,並保持一定的隨機性。這樣可以避免同一時間大量緩存數據同時過期,導致緩存雪崩現象。
緩存標記失效則更新數據緩存緩存標記策略:爲每個緩存數據增加相應的緩存標記,使數據邏輯上永不過期。只有當緩存標記失效時才會更新數據緩存。這種策略可以減少大規模緩存失效的概率。
多級緩存:二級緩存更新一級緩存多級緩存策略:采用多級緩存策略,比如在應用程序中使用本地緩存作爲一級緩存,Redis緩存作爲二級緩存。這樣,當一級緩存失效時,可以通過二級緩存快速更新一級緩存,保持數據的及時性和可用性。
第三方插件更新緩存:通過引入第三方插件(如RocketMQ)來協助數據同步和緩存更新。它們能夠在數據源或二級緩存更新時,自動觸發對應的緩存更新操作,確保數據一致性。
END通過以上策略,我們可以有效地解決緩存雪崩問題,保證系統的穩定運行。這些方案各有優劣,大家可以根據自身業務情況選擇最適合的方案。
好了,這就是今天關于Redis經典問題之緩存雪崩的分享。希望對大家有所幫助!如果你有任何問題或建議,歡迎在評論區留言討論。讓我們一起交流和學習,共同進步!
