衆所周知,OpenAI旗下的GPT-4是現如今世界上最頂尖的大模型(LLM),但就在本周,有關測試表明,GPT-4“霸主”的地位已經被奪走了。
這個超越GPT-4的大模型叫Claude 3。
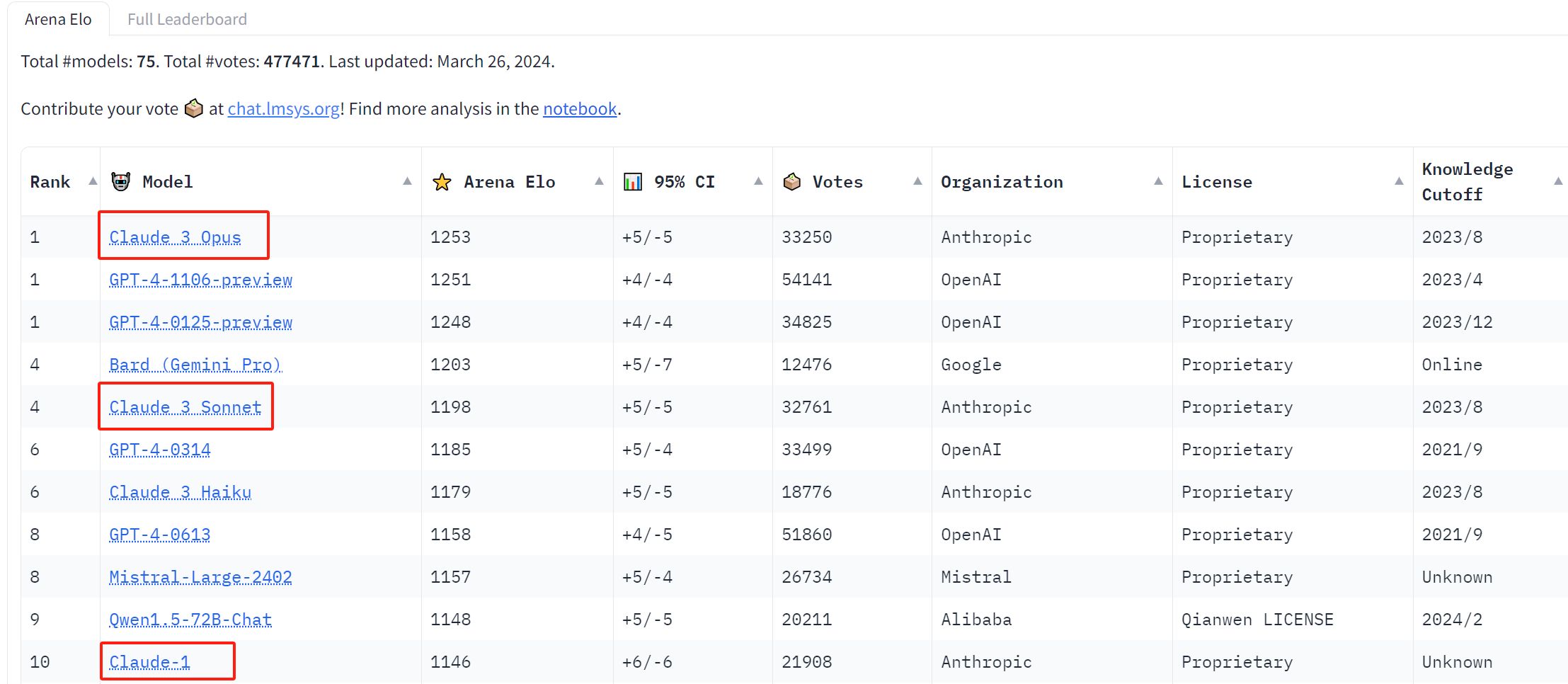
本周,人工智能初創企業Anthropic旗下的Claude 3 Opus在Chatbot Arena(一個測試和比較不同人工智能模型有效性的網站)的最新排名中,首次超越GPT-4,位列排行榜第一。
3月初,Anthropic宣布推出Claude 3大模型系列。該系列包括三個型號,按照性能從弱到強分別是Claude 3 Haiku、Claude 3 Sonnet和Claude 3 Opus。而在Chatbot Arena最新的排行榜上,Claude 3系列三個大模型均闖入TOP 10。
此前,根據Anthropic介紹,其最智能的模型Claude 3 Opus在人工智能系統的大多數常見評估基准上都優于同行,包括本科水平專家知識(MMLU)、研究生水平專家推理(GPQA)、基礎數學 (GSM8K) 等。官方稱:“Claude 3 Opus在複雜任務上表現出接近人類水平的理解力和流暢性。”
當時Anthropic就表示,在多項指標上,Claude 3已經展現出接近或者優于GPT-4或是Gemini 1.0的性能。此次第三方的測試結果再次佐證了Anthropic的這句話。
Chatbot Arena于去年5月推出,由大型模型系統組織(Large Model Systems Organization,簡稱“LMYSY Org”)創建。LMYSY Org是由加州大學伯克利分校的學生和教師創立的開放研究組織。創建Chatbot Arena的目的是幫助人工智能研究人員和專業人士了解兩個不同的人工智能LLM在接受相同提示的挑戰時表現如何。
Chatbot Arena是一個衆包平台,這意味著任何人都可以在上面進行測試。在Chatbot Arena的聊天頁面,包含了多達74種不同AI模型,包括Claude 3系列、OpenAI的GPT-4、谷歌的Gemini和Meta的Llama 2等等。
當有用戶進行測試時,系統會要求用戶在底部的提示框中輸入問題。然後會有兩個匿名模型驅動的聊天機器人來回答用戶的問題,這兩個模型被簡單地標記爲模型A和模型B。
在看完兩個回答後,系統會要求用戶進行評價。用戶可以選擇哪個更好,可以對它們進行同等評價,也可以表示兩個都不喜歡。提交評分後,系統才會告訴用戶剛才兩個聊天機器人分別是由什麽大模型來驅動的。

LMYSY Org會統計網站用戶提交的投票,再將總數彙總到排行榜上,顯示每個LLM的表現。據了解,自推出以來,已有超過40萬名用戶成爲Chatbot Arena的裁判,最新一輪排名又吸引了7萬名用戶加入。
根據最新排行榜,Claude 3 Opus共獲得33,250票,第二名GPT-4-1106-preview獲得54,141票。但獲得的評價多,不意味著更強。爲了對LLM進行評級,排行榜采用的是Elo 排名系統,這是國際象棋等遊戲中常用的一種方法,衡量玩家在某些比賽中與其他玩家相比的相對實力。在使用Elo 排名系統後,Claude 3 Opus在“模型強度的置信區間”上以總分1,253在最新的排名中斬獲第一,險勝GPT-4-1106-preview的1,251分。

其中,在“對所有其他模型的平均勝率(假設抽樣均勻且無平局)”一項上,Claude 3 Opus是唯一一個勝率過0.7的。
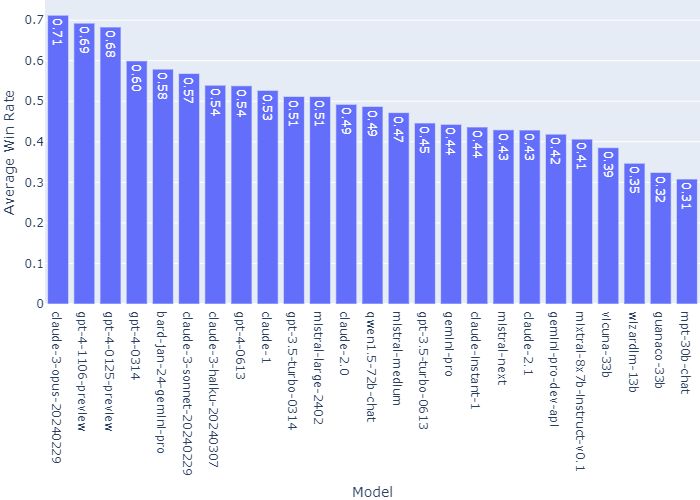
在最新排名中,進入TOP 10的其他LLM包括谷歌的Gemini Pro、Mistral-large-2402和Qwen1.5-72B-Chat等。
隨著GPT-4痛失第一的寶座,Claude 3系列模型均進入前10名,再加上Claude 3系列中最弱Claude 3 Haiku擊敗 GPT-4 0613,Anthropic隨即在整個AI圈引起了轟動。
軟件開發者Nick Dobos在社交媒體上發文直言道:“國王已死。安息吧,GPT-4。”他表示,Claude 3 Haiku擊敗 GPT-4 0613是“瘋狂的”,因爲“它是如此便宜和快速”。

就連LMYSY Org官方也發文稱:“Claude-3 Haiku給所有人留下了深刻的印象,甚至根據我們的用戶偏好達到了 GPT-4級別!其速度、功能和上下文長度目前在市場上是無與倫比的。”