
1. 國際象棋1.1. 1997年計算機“深藍”(Deep Blue)擊敗了頂尖國際象棋手,但機器取代數學研究機構還言之尚早1.2. 下國際象棋與數學的形式化證明頗有相似之處,但學者認爲中國圍棋的思維方式更能夠體現數學家思考的創造性和直覺力1.3. 國際象棋與圍棋相比,則是隨著棋子一個個被吃掉,棋局變得越來越簡單1.4. 計算機科學家克勞德·香農(Claude Shannon)估計的國際象棋走法數量約爲120位(稱爲香農數)1.5. 國際象棋的行棋步驟以一種可控、有序的方式逐級建立分支,最終形成一個包含各種可能性的樹狀結構,計算機甚至人類都可以根據邏輯規則逐級分析不同分支的蘊含關系1.6. 國際象棋更容易進行得分評價1.6.1. 國際象棋是破壞性的,在行棋過程中,棋子會被一個個吃掉1.6.2. 棋局會逐步簡化2. 圍棋2.1. 圍棋很像數學,可以在相當簡單的規則下形成精妙絕倫、錯綜複雜的推理2.2. 據美國圍棋協會(American Go Association)估計,圍棋的可能走法數量是一個大約有300位的數字2.3. 圍棋就不是一種易于推算下一步行棋對策的遊戲了,我們很難建立圍棋行棋可能性的樹狀圖2.4. 圍棋棋手推演下一步落子策略的過程似乎更依賴于自身的直覺判斷2.5. 圍棋最重要的一點,是可以通過客觀的方法檢驗新的行棋思路是否具有價值2.6. 人類的大腦可以敏銳地捕捉到視覺圖像所呈現出的結構和模式,所以圍棋棋手可以通過觀察棋子布局來推斷棋勢,然後得出下一步的應對策略2.6.1. 人類大腦的視覺結構處理能力作爲一種基本的生存技能,經過數百萬年的進化已經變得高度發達2.6.2. 任何動物的生存能力在一定程度上都取決于它在形態萬千的自然界中對不同結構圖像的識別能力2.6.2.1. 原本平靜的叢林之中激起的一絲混亂,極有可能預示著另一種動物的潛入2.6.2.2. 這類敏感信息備受動物們的關注,因爲它關系到自己會成爲獵物還是獵食者,這就是大自然的生存法則2.6.2.3. 人類的大腦非常擅長識別模式並預測它們的發展方向,同時做出適當的反應2.7. 計算機程序學習下圍棋非常困難的主要原因之一,因爲到目前爲止,還沒有一種簡單易行的方法可以建立起一套穩妥的系統,去評價對弈雙方的領先狀況2.7.1. 圍棋則不然,它是建設性的,行棋越多,棋盤上的棋子越多,棋局也越來越複雜2.8. 對圍棋下法的革新一直持續不斷、屢見不鮮2.8.1. 最近一次是圍棋界的傳奇人物吳清源大師于20世紀30年代開創的新棋法,他的布局之法顛覆了傳統圍棋布局的常用套路2.8.2. AlphaGo可能會引發一場更大的圍棋“革命”2.8.2.1. 雖然人類已經發明圍棋數千年了,但人工智能技術的出現讓我們感覺到人類對圍棋的理解仍然還很膚淺2.9. 局部極大值2.9.1. 圍棋算法是陷入數學家們所說的“局部極大值”的困境當中的2.9.2. 圖
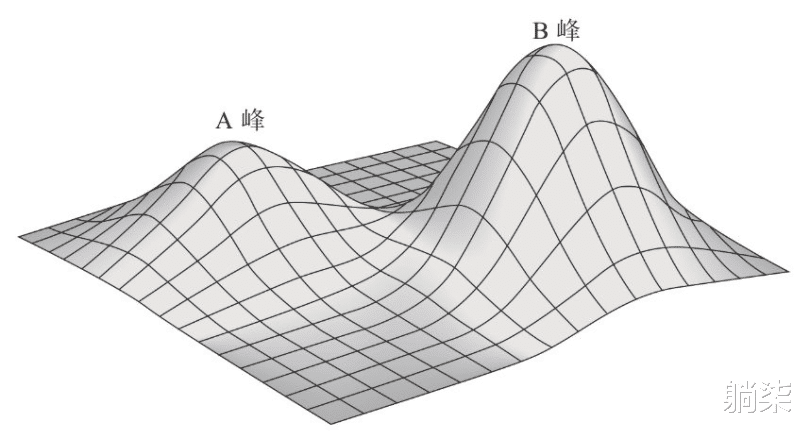
2.9.3. 在傳統棋法的影響之下,圍棋已發展出固有的一套成規,應用好這些規則的確能讓棋手登上A峰2.9.4. AlphaGo的出現撥開了迷霧,打破了這些規則對思維的束縛,使我們看到了更高的B峰2.9.4.1. AlphaGo使用了一些新手都不會用的低級招式2.9.4.2. 傳統下法中棋手不會在三行三列交叉點上落子,但AlphaGo卻向我們展示了如何利用好這一招並爲整個棋局帶來新的機遇2.9.5. 圍棋比賽的統計資料顯示,使用傳統下法的棋手通常會輸給使用新下法的棋手兩子3. 戴密斯·哈薩比斯3.1. Demis Hassabis3.1.1. 雖然劍橋大學破格錄取了他,但由于年齡太小,學校要求他晚一年入學3.1.2. 課堂上教授卻反複強調:“圍棋極具創造性和直覺性,計算機永遠下不好圍棋。”3.1.3. 當他從劍橋畢業時,他決心通過自己的努力來證明教授的言論是錯誤的3.2. 與其編寫一個會下圍棋的程序,不如編寫一個通用性的“元程序”,它可以用于編寫出會下圍棋的程序3.3. 重點是“元程序”在實現以後將具有模式學習能力,隨著經曆的棋局越來越多,該程序會在下棋過程中自我學習,不斷地從錯誤走法中總結經驗並加以改進3.4. 新生兒的大腦並沒有預先設定應對生存挑戰的方法,但他們會通過不斷學習來強化自我,根據環境的變化做出適當的調整3.4.1. 了解大腦的工作原理有助于實現自己創建一個會下圍棋的計算機程序的夢想3.5. 把人工智能算法比作哈勃望遠鏡,認爲它是一種可以用來探索比以往更深、更遠、更廣領域的工具3.5.1. 它會提升而不是取代人類的創造力3.6. 考慮到未來的發展,哈薩比斯決定將公司賣給谷歌3.6.1. 本來我們並不想這麽做,但在過去3年裏,爲了籌措資金,我只有10%的時間用于研究。所以,我意識到,我的人生可能沒有足夠的時間,既能把公司發展成谷歌那樣的規模,又可以在人工智能領域有所建樹。這樣的選擇對我來說並不難3.6.1.1. 哈薩比斯3.6.2. 【躺柒】評:既要..也要..,最後很可能啥都沒有;舍得,舍得,有舍才有得;在每天時間總量不變(1天24小時)或者人生時長有定數(神龜雖壽 猶有竟時)的情況下,就看如何分配了4. DeepMind4.1. 2010年9月,哈薩比斯與神經學家謝恩·萊格(Shane Legg)與穆斯塔法·蘇萊曼(Mustafa Suleyman,哈薩比斯從小一起長大的好友)三人創建了公司,即DeepMind4.1.1. 只有埃隆·馬斯克(Elon Musk)、彼得·蒂爾(Peter Thiel)等極少數的投資人看好這家公司的前景並注入了資金4.2. 在開始階段選擇了一個相對簡單的目標:20世紀80年代的雅達利(Atari)遊戲4.2.1. 雅達利遊戲的複雜性不可與古老的中國圍棋同日而語4.3. 打磚塊遊戲是一個完美的測試用例,可以檢驗DeepMind團隊是否具備開發能夠學會玩遊戲的程序的能力4.3.1. 該程序不會預先設定遊戲規則,而是通過隨機選擇不同的“動作”(比如在打磚塊遊戲中移動球拍或是在Space Invaders遊戲中發射激光炮射擊外星人)不斷試驗,對相應的得分情況進行評估,分析其結果是有效提升還是止步不前4.3.2. 該程序的實現基于20世紀90年代提出的強化學習(reinforcement learning)思想,目的在于根據分數的反饋或獎勵函數來調整執行動作的概率4.3.3. 新的算法將強化學習與神經網絡相結合,後者將評估像素的狀態以確定哪些特征與加分有直接關系4.3.4. 程序在不斷試驗的過程中,可以真正學會通過特定的移動來提高它在遊戲中的得分4.3.5. 現在計算機程序不僅做到了,而且還做得更快、更好4.4. 對他們而言,只針對一款遊戲編寫程序有些太簡單了4.4.1. 到了2014年,也就在DeepMind成立4年後,該項目在已經涉足的49款雅達利遊戲的29款中獲得了優于人類玩家的表現4.5. 該團隊在2015年初向《自然》雜志提交的論文中詳細介紹了他們的研究成果4.5.1. 在《自然》雜志上發表論文是科學家在科研事業上的重要裏程碑,可DeepMind團隊的論文不僅獲得了極高的贊譽,還登上了雜志的封面4.5.2. 這是人工智能發展史上的重要時刻。4.5.2.1. 《華爾街日報》評論4.6. DeepMind團隊現在把目光投向了其他領域:醫療保健、氣候變化、能源效率、語音的生成和識別、計算機視覺5. AlphaGo5.1. AlphaGo是戴密斯·哈薩比斯(Demis Hassabis)智慧的結晶5.2. 唐納德·米基5.2.1. Donald Michie5.2.2. 人工智能研究員5.2.3. 20世紀60年代米基編寫了一個名爲“MENACE”的算法,該算法可以零基礎學習玩井字棋遊戲的最佳策略(MENACE代表導出〇和×策略的引擎)5.3. 此前人們開發的下圍棋程序,甚至很難與業余的優秀圍棋選手相匹敵5.3.1. Crazy Stone是唯一一款接近高水平棋手的圍棋程序5.4. 2015年10月,他們決定組織一場非公開的人機對弈來測試程序,對手是當時的歐洲冠軍——來自中國的樊麾5.4.1. 在世界圍棋比賽中,歐洲頂級選手只能位列600名左右5.4.2. 好比制造出一輛無人駕駛汽車然後在銀石賽道上擊敗了人類選手駕駛的福特嘉年華,並不意味著它能在F1大獎賽中戰勝劉易斯·漢密爾頓(Lewis Hamilton)5.5. 在某些特定參數配置下,AlphaGo似乎完全無法評估出到底是誰掌控了比賽,常常會産生一種錯覺,以爲自己贏了,而實際情況卻恰恰相反5.6. 對于一般的基于開放式數據庫的程序來說,不按套路出牌的策略非常管用5.6.1. 不僅可以使機器手足無措,還可能誤導機器在棋局的重要關口或是長遠戰略決策上犯下致命錯誤5.6.2. 遇到AlphaGo,這個如意算盤可就打空了5.6.2.1. AlphaGo可以實時動態評估棋局形勢,並根據以前的經驗制定出最佳策略5.7. 帶來希望,是因爲正是人類的這種情緒反應激勵著我們去探索未知、開創未來,畢竟還是人類給AlphaGo編寫了制勝的代碼5.7.1. 感到憂心,是因爲機器太過“冷漠”,它根本就不關心事情發展的最終結局是不是程序編寫者所期望的5.8. 從表面上看,AlphaGo所能做的僅僅是下圍棋,但實際上,它的學習和適應能力才是最值得人類關注的一種全新的東西5.8.1. 登月並沒有産生關于宇宙的非凡的新突破,但卻意味著我們爲實現這一壯舉而開發的技術産生了非凡的新突破5.9. 真正的洞察力源于對棋局的綜合把控5.9.1. 這些棋類遊戲現在已經成爲挖掘新思想的寶庫6. 李世石九段對陣谷歌AlphaGo五番棋賽6.1. 在酒店內的比賽現場卻是封閉和保密的6.1.1. 媒體和現場觀衆的任何行爲都不會讓AlphaGo分心,因爲機器無論在什麽狀態下,都會保持“禅宗大師”一般的定力,呈現出一種完美的專注狀態6.2. 第一局6.2.1. 第一局比賽中AlphaGo所走的每一步棋還是符合人類邏輯思維的,現場的專家也能夠講解和分析棋局6.2.2. 李世石執黑先行,作爲白方的DeepMind團隊由其成員黃士傑(Aja Huang)代替AlphaGo行棋6.2.2.1. 畢竟AlphaGo只是人工智能程序而不是能夠自己下棋的機器人6.3. 第二局6.3.1. AlphaGo下出第37手:黃士傑在距離棋盤邊緣5步的位置落下一顆黑子6.3.1.1. 這一招使得包括李世石在內的所有人都倍感震驚6.3.1.2. 在第5條線上落子一般被認爲是不太恰當的選擇6.3.1.2.1. 因爲這會給對手可乘之機:建立一個既可在短效、局部區域內搶得先手,又可在長遠、全局範圍內影響勝負的策略6.3.1.3. 這確實不是人類的行棋方法6.3.1.4. 這一著非但不是臭棋,反而是立意深遠的妙手6.4. 第三局6.4.1. 怠惰走法(lazy moves)的策略6.4.1.1. 通過分析,AlphaGo確信自己最終可以獲勝,正因爲如此,它選擇了這種安全的策略6.5. 第四局6.5.1. 李世石采用了一種更爲激進、極端的“先撈後洗”(amashi)的策略6.5.2. “勝負手”(all-or-nothing)策略可能會讓AlphaGo更難輕易得分6.5.3. 當AlphaGo的棋路開始變得保守,頻頻使用怠惰走法時,就標志著AlphaGo已經確認自己領先了6.5.4. 第78手就是李世石的逆襲大招6.5.4.1. 當AlphaGo意識到自己失敗後,會做出一些令人費解的瘋狂行爲6.5.4.2. AlphaGo的行爲沒有通過圖靈測試,因爲任何一個具有戰略眼光的人都不會做出那樣的決策6.5.4.3. 這一步棋打破了傳統棋路,是爲整局比賽帶來深遠影響的關鍵所在6.5.4.3.1. ‘上帝之手’6.5.4.4. AlphaGo與人類對弈的曆史經驗讓它完全摒棄了某些思考6.5.4.4.1. 根據它的評估,那種下法只有萬分之一的可能性會出現6.6. 第五局6.6.1. 經過第四局,AlphaGo也收獲頗豐6.6.1.1. 現在就算李世石在第10 000手下出違反常規的怪招,它也不會再想著僥幸過關了6.7. 李世石認爲不只機器可以學習和進化,人也可以從失敗中學到一些東西6.7.1. 與一群職業棋手分析和探討此前兩場比賽中失利的原因,這場討論一直持續到次日清晨6點6.8. 算法的強大之處:從錯誤中吸取教訓,進而反敗爲勝6.8.1. 並不意味著AlphaGo不會再犯新的錯誤7. 向人類宣戰7.1. 我們在持續重構世界秩序,直覺始終被尊崇。7.1.1. 保羅·克利(Paul Klee)7.2. 只在局部環境中按部就班地進行邏輯分析走不了太遠,必須與發現“可能存在物”的直覺相結合才有可能取得顯著的突破7.2.1. 有些數學猜想雖然未得到證明,但提出猜想的數學家經常能感覺到在他的論述中暗含著某種真理7.2.2. 善于提出好的猜想的數學家比善于證明猜想的數學家更值得尊敬7.2.3. 束縛我們認知的障壁,會在計算機技術日新月異的發展中被瞬間攻破7.3. 一些在誕生之初就受到指摘的事物,往往經曆幾代人才會逐漸被接受並被視爲具有革命性的創新7.3.1. 並不被19世紀的人們所認可或知曉的貝多芬的交響樂,現在被譽爲藝術的巅峰7.3.2. 凡·高的一生中,幾乎沒有售出過畫作,它們只能用來交換食物或繪畫材料,但現在他的大作卻可以賣出數百萬美元的高價7.4. 當我們得知再怎麽努力也只能成爲屈居于機器之後的第二梯隊棋手時,確實會意志消沉7.4.1. 雖然機器的程序還是人編寫的,但這也不會讓人有挽回顔面的感覺7.5. DeepMind團隊將要開發出來的程序居然有可能讓數學家丟掉飯碗,而創造這些程序的工具正是數學家們曆經幾個世紀的不懈努力才發現和創造出來的
