編輯:LRS
【新智元導讀】大模型最爲人诟病的問題就是不透明、不可解釋。谷歌的最新框架Patchscopes可以提供關于模型內部隱藏表征的自然語言解釋,本文介紹了一些實戰應用樣例。雖然大型語言模型(LLM)在各種常見的自然語言處理任務中展現出了優異的性能,但隨之而來的幻覺,也揭示了模型在真實性和透明度上仍然存在問題。
在模型生成錯誤回複內容時,如果能夠「深入理解其背後運行機制」,或許可以解決模型的幻覺問題。
然而,隨著深度神經網絡的複雜性和規模的增長,模型的「可解釋研究」也越來越有挑戰性,通過探索機器學習(ML)模型對所學內容(模型的所謂隱藏表示)進行表征的方式,即隱藏表征(hidden representation),研究人員可以在一定程度上控制模型的行爲,並對模型的實際運行方式進行更深入的科學理解。
從過去的研究結果來看,一個相對有前景的方向是「使用LLMs來解釋其他模型的神經元模式」(neuron patterns)。
今年1月,Google Research和特拉維夫大學的研究人員共同提出了一個統一的框架Patchscopes來研究LLMs中的隱藏表征,主要思路就是使用LLMs來提供有關模型本身內部隱藏表征的自然語言解釋。

論文鏈接:https://arxiv.org/pdf/2401.06102.pdf
Patchscopes統一並擴展了現有的可解釋性技術,能夠讓模型回答出之前無法解決的問題,比如模型可以說出關于「LLM的隱藏表征如何捕捉模型輸入中含義的細微差別」的見解和想法,從而幫助開發人員更容易地修複某些特定類型的推理錯誤。
在論文剛發布的時候,研究人員還只是將Patchscopes的應用場景集中在自然語言處理領域和自回歸Transformer模型家族中,但實際上該方法的潛在應用範圍更廣。
最近,研究人員又發布了一篇博客,詳細介紹了該方法在檢測和糾正模型幻覺、探索多模態(圖像和文本)表征以及研究模型如何在更複雜的場景中構建預測方面的應用樣例。
Patchscopes使用方法以NLP中常見的「實體共同指代解析」(co-references to entities)任務爲例,首先需要在Patchscopes中實現一個專門用于解決共指問題的工具。
比如說,爲了研究模型對代詞「it」所指代的人物上下文是如何理解的,需要創建出一套Patchscopes配置。
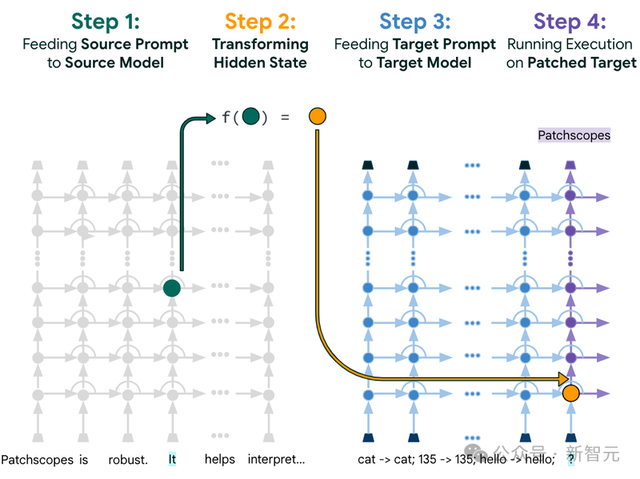
Patchscopes框架圖解,通過使用預定義的目標提示符(右)解碼源提示符(左)中「It」表征中編碼的內容。
1. 設置 Setup
給定一個目標模型後,需要輸入一段包含相關上下文信息的標准提示(即源提示,source prompt),如“Patchscopes is robust. It helps interpret…"(Patchscopes是穩健的,有助于解釋…)
2. 目標 Target
二級提示(secondary prompt 即 target prompt)的目的是提取特定的隱藏信息,在這個例子裏,一個簡單的單詞重複提示就可以揭示出隱藏表征中的信息。
例子中的目標提示詞是「cat->cat; 135->135; hello->hello; ?」,但需要注意的是,提示中的單詞是隨機選擇的,所以可能看起來和輸入文本不相關,但也需要遵循特定的編寫模式:包含多個例子,其中每個樣例包括一個單詞、一個箭頭以及對該單詞的重複。
如果將文本輸入到一個訓練後的語言模型中來預測下一個單詞,模型的預期輸出爲能夠繼續遵循該模式。
換句話說,如果模型把「?」中的內容與其他隨機單詞進行替換,讓模型生成下一個單詞,以此來考察模型應該重複哪些單詞?
3. 塊 Patch
在源提示符上執行推理(inference),其中「It」token中感興趣層的隱藏表征(圖中的綠色點)被注入到目標提示(圖中的橙色點)上,可以應用transformation(示例中的f函數)將表征與其他層或模型對齊。
4. 揭示 Reveal
對于增強後的輸入(augmented input),模型會在輸出中包含原始模型是如何在特定上下文中在內部對單詞「It」進行擴展的想法。
給出的例子中,模型生成了「Patchscopes」,解釋了在「It」token之上的模型第四層的隱藏表征,結果表明,經過4層計算後,模型已經將來自先前單詞的信息合並到「It」token上方的隱藏表征中,並得出結論,其不再指代通用對象,而是指代「Patchscopes」。
雖然token表征(綠色點)可能看起來像一個沒有任何含義解的浮點數向量,但Patchscopes框架可以將其轉換爲人類可理解的文本,表明指代的是「Patchscopes」,與先前的工作一致,即關于一個主題的信息會在其最後一個token中累積。
Patchscopes實戰Patchscopes在理解和控制LLMs方面有廣泛的應用。
1. 下一個token預測(next token prediction)
在計算過程中,根據給定的上下文,模型可以「多早地」得出最終預測?
從中間隱藏表示進行的token預測是一個常見的、可用于評估查看Transformer內部的可解釋性方法。
即使是在更複雜的早期或中期處理層,Patchscope的效果也非常好:在不同的語言模型中,從第10層開始,其性能都優于之前的方法,如Tuned Lens和Logit Lens。

使用來自LLM的中間隱藏表征的下一個token預測任務來評估各種可解釋性方法,展現了使用一個簡單的「Token Identity」目標提示符(即,由k個表示類似于標識的函數的演示組成的目標提示符,格式爲「tok_1 → tok_1 ; tok_2 → tok_2 ; ... ; tok_k」)與Tuned Lens和Logit Lens方法相比。x軸是在LLM中檢查的隱藏表征層;y軸顯示precision@1,測量最高概率預測token匹配原始分布中最高概率token示例的比例。
2. 提取事實(pulling out facts)
在模型的計算中,可以多早獲取屬性信息(例如,某個國家的貨幣)。
在這個實驗中,研究人員主要考慮從文本中提取屬性的任務,文本來源爲Hernandez等人(2024年)編寫的常識和事實知識任務。

論文鏈接:https://openreview.net/pdf?id=w7LU2s14kE
使用的目標提示主要針對簡單的動詞化關系,其次是一個占位符的主題。例如,要從「States」的表征中提取美國的官方貨幣,使用目標提示符「The official currency of x」,考慮到Patchscopes應用程序不使用任何訓練示例,並且明顯優于其他技術。

跨源層的屬性提取准確性(Attribute extraction accuracy across source layers,簡寫爲REQ)。左:工具完成的任務(常識),54個源提示,12個類。右:國家貨幣(事實),83個來源提示,14個類別。
3. 解釋實體:不只用yes或no
模型在處理輸入時如何理解像「亞曆山大大帝」(Alexander the Great)這樣的多詞輸入?
Patchscopes超越了簡單的「它已經解決了這個問題」(has it figured this out yet)的答案,揭示了模型如何從開始階段,逐漸理解一個實體。
使用以下few-shot的目標提示來解碼模型的逐步處理:「敘利亞:中東國家,列奧納多迪卡普裏奧:美國演員,三星:韓國跨國大型家電和消費電子公司,x」(Syria: Country in the Middle East, Leonardo DiCaprio: American actor, Samsung: South Korean multinational major appliance and consumer electronics corporation, x)。
當遍曆兩個不同模型(Vicuna-13 B和Pythia-12 B)的層時,更多來自上下文的單詞被整合到當前表征並反映在生成中。

通過定性實例說明實體解析:表達性的生成表明,當通過層時,更多來自上下文的tokens被集成到當前表征中。「解釋」(Explanation)指的是生成與源提示詞的關系。兩個示例都使用了上述相同的目標提示符。
4. 團隊合作:用模型解釋模型
Patchscopes框架可以使用強大的語言模型來解碼較小的過程:研究人員利用Vicuna-13 B來解釋Vicuna-7 B的輸入處理,將隱藏的實體表征從較小的模型修補到較大的模型中,然後測量模型生成的文本和來自維基百科的實際參考描述之間的詞彙相似性(使用RougeL得分)。
Vicuna-7 B → 13 B(綠色線)幾乎總是高于Vicuna-7 B → 7 B(藍線),曲線下面積更大,結果表明,跨模型修補到一個更大的和更有表現力的模型,在改進的生成和參考文本之間的詞彙相似性的結果,並表明跨模型修補的過程顯著增強了模型的能力,生成文本的上下文對齊的輸入表示從另一個模型。

使用Vicuna模型,生成的描述與維基百科的描述的RougeL(詞彙相似性)得分,從Vicuna-7 B到Vicuna-13 B的patched表征導致對popular和rare實體解析以更具表達力的語言化。
5. 修複錯誤推理
雖然最先進的LLMs可以獨立地解決每個推理步驟,但仍然很難實現多步推理。
Patchscopes可以通過重新路由中間隱藏表征來幫助解決這個問題,從而顯著提高准確性:在實驗中,系統地生成多跳的事實和常識推理查詢,並表明,與輸入結構的先驗知識,錯誤可以通過修補隱藏表征從查詢的一部分到另一個固定。

思維鏈(CoT)Pathcscope使用相同的源提示和目標提示來執行順序推理,但將一個位置的隱藏表征修補到另一個位置。
CoT Patchscope將准確率從19.57%提高到50%,本實驗的目的是證明使用Patchscopes進行幹預和糾正是可行的,但要注意CoT Pathscope是一種說明,而不是一種通用的糾正方法。
參考資料:
https://research.google/blog/patchscopes-a-unifying-framework-for-inspecting-hidden-representations-of-language-models/
