大模型就要沒彈藥了,訓練數據成爲大模型升級的最大攔路虎。
《紐約時報》報道,爲了訓練GPT4,OpenAI使用其旗下語音轉文字模型Whisper挖掘了超100萬小時的YouTube數據作爲其訓練模型。而另一端,社交媒體巨頭Meta高層也在討論收購出版社 Simon & Schuster來完成基礎模型對高質量訓練數據的需求。
但即使如此,現有人類社會生成的包含社交文本在內的互聯網數據也不能夠支持大語言模型的優化升級。研究機構Epoch報告,在未來兩年內,AI訓練將用盡互聯網上包含音視頻在內的高質量數據格式,而現存(包括未來生成的)數據集或將在2030年至2060年之間耗盡。
除了物理世界現實存在的數據,科技公司還考慮使用合成數據作爲AI訓練材料。合成數據就是用AI生成的數據訓練大語言模型。不過,合成數據也就意味著更高的計算費用和人才支出,這也讓本就高昂的AI成本雪上加霜。
/ 01 / 最優的數據,最好的大模型
據悉,GPT4有著超1.8萬億參數和13萬億token的訓練數據。
13萬億,相當于自1962年開始收集書籍的牛津大學博德利圖書館存儲的單詞數量的12.5倍。這些數據來源于新聞報道、數字書籍、Facebook社交平台數據。不過在這之前,我們並不知道還有基于視頻轉錄的文字。據傳,Google模型也使用了Youtube轉譯的文字作爲其大模型訓練數據。
不止ChatGPT,市面上的大模型都是建立在上億級模型的訓練基礎上的。谷歌的 BERT是在英語維基百科和BookCorpus中包含33億單詞的數據集上進行訓練的,微軟的 Turing-NLG是在英語網頁中超過170億個詞組的數據集上進行訓練的。
可以說,數據就是AI模型的燃料。根據標度定律(scaling law),訓練模型的數據越豐富,來源愈豐富、異質化愈強,模型的質量越高,語義理解能力越強。這不難理解,AI就像是一個小孩,需要學習大量的課本、報道,而一個學生學習掌握的知識越多,一定程度上就越聰明,能處理的任務就越多。
大模型的數據訓練是一個叠代的過程。2020年之前,大部分的AI模型數據量相對較小,大多在1000萬以下。舉個例子,GPT2的訓練數據就是40G,GPT3的訓練數據則高達570G,約爲GPT2的15倍。高達3000億token的GPT3開啓了大語言模型千億級token訓練的先河。
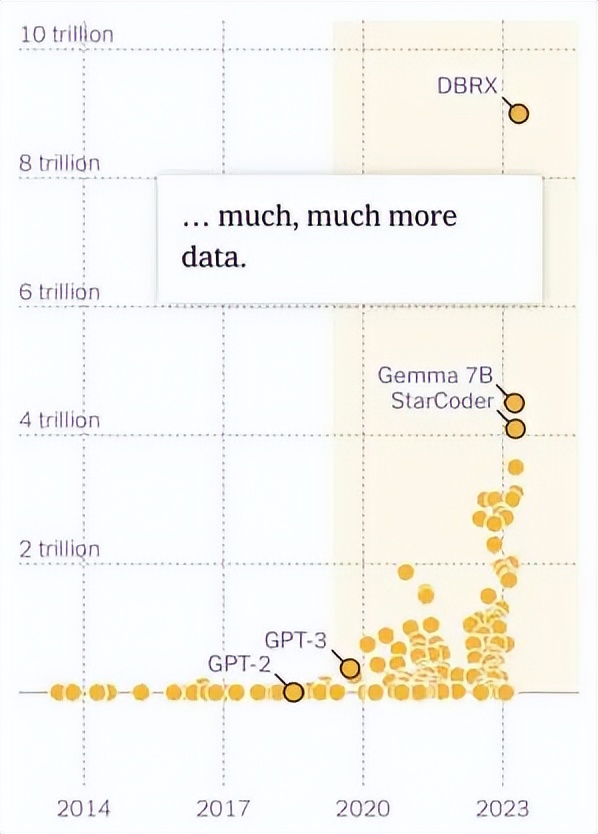
大語言模型訓練數據規模
數據規模固然重要,但數據質量也同樣不容忽視,有失偏頗的數據可能會造成潛在的刻板歧視和偏見,比如最近引起巨大爭議的Meta圖像生成案,不能生成白人女性和亞洲男性同框的圖像。
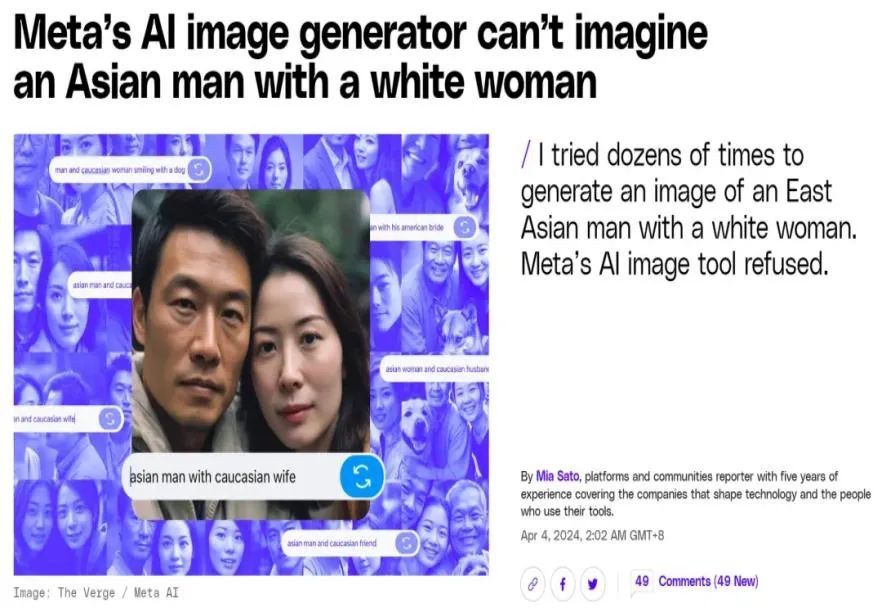
Meta圖像生成器拒絕生成亞洲男性和白人女性的圖片
所以,AI的訓練數據不僅強調量大,更強調樣本的異質性,代表的多樣性。OpenA負責人Peter Deng就曾說過,訓練AI的數據最好能夠體現不同民族、不同文化的價值觀,大模型發展應該避免民族中心主義和文化霸權,特定來源的訓練材料總是有失偏頗的。
最優的大模型需要最好的數據,但是數據也不是天上掉下來的免費午餐。隨著模型升級和巨頭之間的科技軍備賽的白熱化,限制LLM發展的最大攔路虎不再是技術本身,而是最關鍵的也是最容易忽略的因素——數據。
/ 02 / 供不應求,LLM訓練遭遇數據困境
現階段的AI訓練數據主要包括新聞報道、虛構作品、留言板帖子、維基百科文章、計算機程序、照片和播客,比如common crawl,一家從2007年以來收集了超2500億網頁文章的數據庫,有1000TB的數據量。
當下的LLM數據困境,主要體現在兩個方面:
一是高質量數據的規模有限。高質量數據通常包括出版書籍、文學作品、學術論文、學校課本、權威媒體的新聞報道、維基百科、百度百科等,經過時間、人類驗證過的文本、視頻、音頻等數據。
與大模型訓練數據規模每年翻倍不同,這些高質量數據的增長非常緩慢。以出版社書籍爲例,需要經過市場調研、初稿、編輯、再審等繁瑣流程,耗費幾個月甚至幾年時間才能出版一本書。這意味著,高質量數據的産出速度,遠遠落後大模型訓練數據需求的增長。
研究機構Epoch稱,科技公司或將在2026年使用完互聯網上所有可用于模型訓練的高質量數據,包括維基百科、學術期刊論文等高質量數據文本。同時,AI公司使用數據的速度比社會生成數據的速度要快,該機構預計在2030-2060年之間,能用于AI訓練的人類數據將會全部耗盡。
除了高質量數據本身有限外,這些數據獲得難度也在大大提升。由于擔心平補償等問題,社交媒體平台、新聞出版商和其他公司一直在限制AI公司,使用自家平台數據進行人工智能訓練。
去年7月,Reddit 就表示將大幅提高訪問其 API 的費用。該公司的管理人員表示,這些變化是對人工智能公司竊取其數據的回應。Reddit 創始人兼首席執行官 Steve Huffman 告訴《紐約時報》:「Reddit 的數據庫真的很有價值。」「但我們不需要把所有這些價值都免費提供給一些全球最大的公司。」
此前,OpenAI也曾因未經授權使用新聞報道與《紐約時報》打了官司,英偉達也因未經授權使用原創小說遭到美國作家的聯合訴訟。
總的來說,大模型企業已經基本上搜刮了電子數據、新聞報道、社交媒體數據等所有能夠想到的數據來源。而部分明確受到保護的版權作品,科技巨頭在短時間內也難以征得其訓練版權。同時,高昂的版權費可能也會目令前盈利能力微弱的AI公司捉襟見肘。
在這種情況下,科技巨頭紛紛殚精竭慮尋找優質訓練數據餵給自身模型,也就有了OpenAI采集超百萬小時YouTube數據,爲GPT-4提供訓練素材的故事了。
據了解,OpenAI的數據收集策略並不僅限于YouTube視頻。該公司還從Github的計算機代碼、國際象棋走棋數據庫以及Quizlet的作業內容中獲取數據。OpenAI發言人Lindsay Held在一封電子郵件中透露,公司爲其每個模型都策劃了獨特的數據集,以保持其全球研究競爭力。
在最近的一次高層管理會議中,Meta高管甚至還建議收購出版社 Simon & Schuster以采購包括史蒂芬金等知名作家作品在內的長篇小說爲其AI模型提供訓練數據。
出于法律風險、成本等因素的考量,越來越多公司開始嘗試自己制作的訓練數據——合成數據。
/ 03 / AI合成,會是模型訓練的救命稻草嗎?
合成數據是一種通過算法或計算機模型生成的數據,它模擬實際情況,但無需通過收集實際數據來實現,而是讓AI自己生成文本、圖像、代碼再反哺給自己的訓練系統,生成現實世界中難以獲取的數據。
這並不是一個新的概念。合成數據在自動駕駛等領域有著廣泛應用。比如,車企可以通過合成數據模擬真實的駕駛場景,爲自動駕駛系統提供大量訓練數據。
使用合成數據的好處顯而易見。一方面,合成數據可以降低人工收集、處理和標注的成本,提高模型訓練的效率。同時,合成數據一定程度上也突破了非平台企業的數據瓶頸。一直以來,X、Meta、Instagram等社交平台的用戶數據都被微軟、谷歌幾家大頭壟斷。初創公司和小微企業難以獲得訓練自己的AI模型,而合成數據可以通過模擬物理世界的真實行爲合成這些數據,從而降低了初創公司訓練大語言模型的成本。
但與此同時,合成數據的缺點也明顯。作爲一種數據建模解決方案,AI合成數據最大的特征是“全面控制”,從代碼到算法到微調,程序員可以模擬、調控數據生成的整個過程。這也就意味著,合成數據最大的問題是“有失偏頗”。
相比垂直大模型,通用大模型更加強調數據的異質化、差異性和多樣性。但在現階段,AI的智能程度還難以生成具備多樣性、代表性、高質量的訓練數據,畢竟機器生成的數據底層邏輯基于人類程序員的設計,難以反映出大千世界的多元文化。
具體來說,建立在合成數據上的大語言模型不可避免地帶有內嵌的機器學習思維,而訓練數據中合成數據的占比越大,自然語言理解能力或許就越低。這也是AI界固有存在的hallucination幻覺問題,即生成與人工指令prompt不符的胡言亂語。
更不用說,大模型還不可避免地帶有人類社會固有的偏見(比如種族歧視、文化霸權等),比如今年二月份谷歌通用人工智能助手生成的黑人納粹軍隊圖像。如果基于已經存在其實的模型數據繼續訓練,生成的數據可能會進一步放大這種誤差與偏見。
可以說,AI始于數據,也困于數據。在高質量數據受到版權壓力,合成數據面臨質量爭議的情況下,大模型訓練將面臨更多的考驗。
不過好在大模型企業仍然對合成數據的應用前景表示樂觀。據了解,OpenAI和Anthropic的研究人員正試圖通過創建所謂的更高質量的合成數據來避免這些問題。在最近的一次采訪中,Anthropic的首席科學家JaredKaplan表示,某些類型的合成數據可能會有所幫助。
未來,大模型的數據困境將會從何突破,我們將會持續關注。

