編輯:編輯部
【新智元導讀】最大開源模型,再次刷爆紀錄!Snowflake的Arctic,以128位專家和4800億參數,成爲迄今最大的開源模型。它的特點,是又大又稀疏,因此計算資源只用了不到Llama 3 8B的一半,就達到了相同的性能指標。就在剛剛,擁有128位專家和4800億參數的Arctic,成功登上了迄今最大開源MoE模型的寶座。
它基于全新的Dense-MoE架構設計,由一個10B的稠密Tranformer模型和128×3.66B的MoE MLP組成,並在3.5萬億個token上進行了訓練。
不僅如此,作爲一個比「開源」更「開源」的模型,團隊甚至把訓練數據的處理方法也全給公開了。

Arctic的的兩個特點,一個是大,另一個就是非常稀疏。
好處就在于,這種架構讓你可以用比別人少好幾倍的訓練開銷,就能得到性能差不多的模型。
也就是說,與其他使用類似計算預算訓練的開源模型相比,Arctic的性能更加優異。
比起Llama 3 8B和Llama 2 70B,Arctic所用的訓練計算資源不到它們的一半,評估指標卻取得了相當的分數!

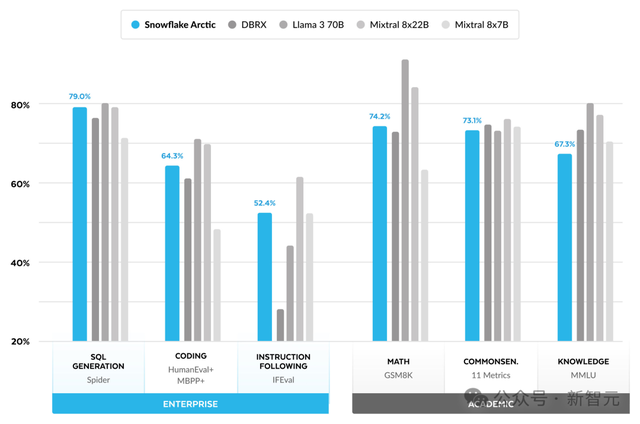
圖1 編碼(HumanEval+和MBPP+)、SQL生成(Spider) 和指令遵循(IFEval)的企業智能平均值與訓練成本的比較
具體信息如下——
480B參數,生成期間17B處于活躍狀態;
128位專家,有2位在生成期間活躍;
Instruct & Base版本發布;
專注于企業任務(代碼、SQL、推理、跟蹤);
在Apache 2.0下發布;
FP16精度下約爲900GB內存,INT4精度下約爲240GB內存
使用DeepSpeed-MoE訓練。

主打的就是一個性價比
評測主要看兩項指標,一個是企業智能指標,一個是學術基准。
企業智能指標,是對企業客戶至關重要的技能,包括包括編碼(HumanEval+和MBPP+)、SQL生成(Spider)和指令遵循(IFEval)。
同時,團隊也采用了業界常用的評估LLM的學術基准,包括世界知識、常識推理和數學能力。
可以看到,Arctic在多項企業智能指標中,都超越了Mixtral 8×7B等開源對手。
在計算類別中,它實現了頂級性能,甚至和使用更高計算預算訓練的模型,都有的一拼。
在學術基准上,它的表現也不差。
在測評中,團隊發現了一件有意思的事。
MMLU等世界知識指標,是人們常用的學術基准測試。而隨著高質量網絡和STEM數據的增加,MMLU的得分會隨著訓練FLOPS的增加而提高。
但是,Arctic的目標之一,是在保持較小訓練預算的同時優化訓練效率,因此,跟其他模型相比,Arctic在MMLU上的得分較低,也實屬情理之中。
由此,如果訓練計算預算高于Arctic的訓練,MMLU性能就將超越Arctic。
當然,MMLU世界知識的性能,並不一定和團隊所關注的企業智能直接相關。
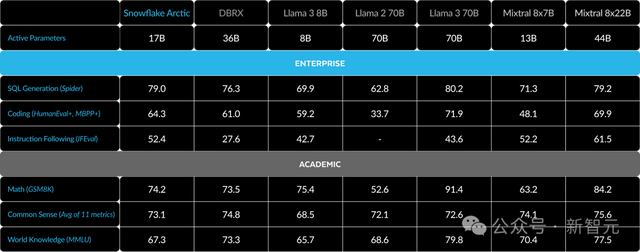
表3 Arctic與DBRX、Llama 3 8B、Llama 3 70B、Mixtral 8x7B、Mixtral 8x22B的對比
企業級AI的訓練成本,被打下來了!
在以往,用LLM構建頂級企業AI的成本,往往高得離譜,而且需要大量資源,令人望而卻步。
通常,花費的成本高達數千萬甚至數億美元,這一成本是驚人的。
如何解決有效訓練和推理的限制?Snowflake AI團隊的研究者一直在做這方面的努力,團隊成員過去曾開源了ZeRO、DeepSpeed、PagedAttention/vLLM和LLM360等系統,顯著降低了LLM訓練和推理的成本。

而今天推出的Arctic,在SQL生成、編碼和遵循基准指令等企業任務上,表現非常出色。
它爲具有成本效益的訓練設定了新的基准,用戶可以以極低的成本,就能創建滿足企業需求的高質量定制模型。
Arctic也是一個真正的開放模型,在Apache 2.0許可下,提供對權重和代碼的無限制訪問。
從今天開始,Snowflake Arctic就可以從Hugging Face上獲取了。
計算資源僅用一半,表現卻和Llama 3 8B相當團隊發現,企業客戶對AI有著一致的需求和使用場景——構建對話式SQL數據助手、代碼助手和RAG聊天機器人。
爲了便于評估,團隊通過對編碼(HumanEval+和MBPP+)、SQL生成(Spider)和指令跟隨(IFEval)取平均值,將這些能力整合到「企業智能」這個單一指標中。
在開源LLM中,Arctic僅用不到200萬美元(相當于不到3000個GPU周)的訓練計算預算,就實現了頂級的企業智能。
更重要的是,即使與那些使用顯著更高計算預算訓練的模型相比,它在企業智能任務上也表現出色。
結果顯示,Arctic在企業級評估指標上的表現,與Llama 3 8B和Llama 2 70B相當,甚至更優,而它所使用的訓練計算資源卻不到後兩者的一半。
具體來說,Arctic使用的計算預算只有Llama3 70B的1/17,但在編程(HumanEval+和MBPP+)、SQL(Spider)和指令跟隨(IFEval)等企業級任務上,都與其不相上下。
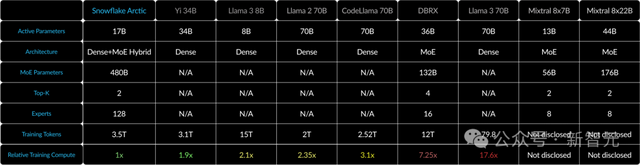
表1 Arctic、Llama-2 70B、DBRX和Mixtral 8x22B的模型架構和訓練計算量(與活躍參數和訓練token的乘積成正比)
此外,Arctic的高訓練效率還意味著,Snowflake客戶和整個AI社區可以以更加經濟實惠的方式訓練定制模型。
訓練效率爲了實現如此高的訓練效率,Arctic采用了獨特的Dense-MoE Hybrid transformer架構。
該架構將一個10B規模的稠密Transformer模型與一個128×3.66B規模的殘差MoE MLP相結合,雖然總參數量達到480B,但通過top-2 gating的方式只選擇了其中17B個參數保持活躍。
Arctic的設計和訓練基于以下三個關鍵創新:
1. 更多但精煉的專家,以及更多的專家選擇
首先,DeepSpeed團隊在2021年末便證明了,MoE(Mixture of Experts)可以在不增加計算成本的情況下,顯著提高LLM模型的質量。
其次,模型質量的提升主要取決于MoE模型中專家的數量、總參數量以及這些專家可以組合在一起的方式和數量。
基于此,Arctic被設計爲擁有480B個參數,分布在128個細粒度專家中,並使用top-2 gating選擇17B個活躍參數。相比之下,最近的MoE模型使用的專家數量就要少得多了(如表2所示)。
從直觀上看,Arctic利用更大的總參數量和衆多專家來擴大模型容量,同時更明智地在衆多精煉的專家中進行選擇,並使用適度數量的活躍參數來實現資源高效的訓練和推理,最終獲得頂級的智能。
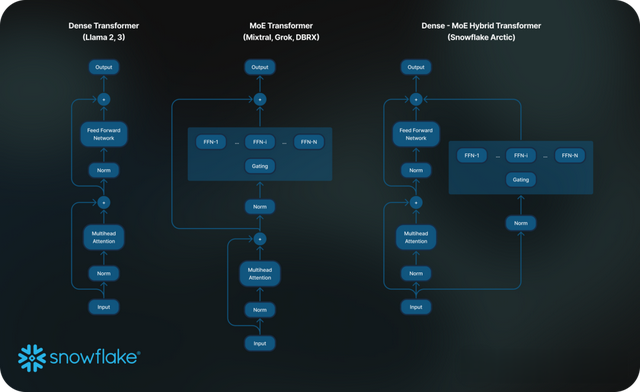
圖2 標准MoE架構 vs. Arctic
2. 架構和系統協同設計
即便是用最強大的AI硬件,想要基于普通的MoE架構訓練大量專家效率依然很低。
其原因在于,專家之間存在的全通信開銷非常高昂。不過,如果能將通信與計算重疊,那麽就可以極大地降低這種開銷。
因此,團隊在Arctic架構中將一個密集的Transformer與一個殘差MoE組件(圖2)相結合,從而使系統能夠通過通信計算重疊來消除大部分通信開銷,最終實現了極佳的訓練效率。
3. 面向企業的數據課程
要在代碼生成和SQL等企業指標上表現出色,需要與訓練通用指標的模型截然不同的數據課程。
團隊在進行了數百次小規模的對比實驗後發現,常識推理等通用技能可以在開始時學習,而編碼、數學和SQL等更複雜的指標可以在訓練的後期有效學習。
因此,Arctic采用了三階段課程進行訓練,每個階段的數據組成不同——
第一階段(1T Tokens)側重于通用技能,後兩個階段(1.5T和1T Tokens)側重于企業級技能。

表2 Arctic三階段訓練的動態數據組成
推理效率訓練效率,只是Arctic高效的其中一個方面。
如果希望低成本部署模型,推理效率也同樣至關重要。
作爲MoE模型規模的飛躍,Arctic使用了比其他開源自回歸模型更多的專家和參數。
因此,爲了有效地在Arctic上運行推理,團隊做了一些系統性的創新——
a) 在較小batch的交互式推理中(比如批大小爲1),MoE模型的推理延遲受到了讀取所有活躍參數所需時間的瓶頸,其中,推理是受內存帶寬限制的。
在這樣的批大小下,Arctic(17B活躍參數)的內存讀取次數比Code-Llama 70B少4倍,比 Mixtral 8x22B(44B活動參數)少2.5倍,從而實現更快的推理性能。
爲此,團隊跟英偉達的TensorRT-LLM和vLLM團隊展開合作,爲交互式推理提供了Arctic的初步實現。
通過FP8量化,團隊可以將Arctic放入單個GPU節點中。
雖然仍遠未完全優化,但在批大小爲1時,Arctic的吞吐量超過70+token/秒,這樣就實現了有效的交互式服務。
b) 當批大小的規模顯著增加,例如每次前向傳遞要處理數千個token時,Arctic就會從內存帶寬受限轉變爲計算受限,此時推理的瓶頸就在于每個token的活躍參數。
在這一點上,與CodeLlama 70B和Llama 3 70B相比,Arctic的計算需求減少了4倍。
爲了實現計算受限的推理和與Arctic中活躍參數數量較少相對應的高吞吐量(如下圖所示),需要較大的batch size。
要實現這一點,需要有足夠的KV緩存內存來支持較大的batch size,同時也需要足夠的內存來存儲近500B的模型參數。
面對這重重挑戰,最終團隊還是找到了辦法。
通過使用FP8權重、分割融合和連續批處理、節點內的張量並行性以及節點間的管線並行性等系統優化組合,團隊在雙節點推理中,實現了這一目標。
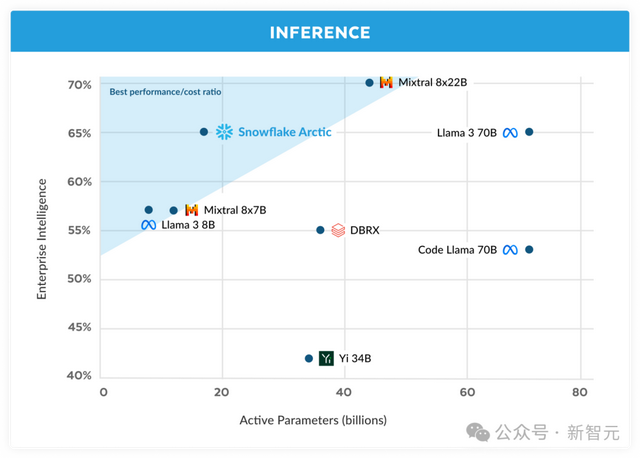
圖3 推理期間編碼(HumanEval+和MBPP+)、SQL生成(Spider)和指令跟蹤 (IFEval)企業智能的平均值與活躍參數的對比
開源代碼
新模型Arctic基礎模型和指令微調模型代碼全部開源,任何人可以將其用于研究、産品、原型當中。
項目地址:https://github.com/Snowflake-Labs/snowflake-arctic
研究人員基于LoRA的微調的pipeline和配方(recipe),並允許在單個節點上進行高效的模型微調。
現在,Snowflake正在與英偉達TensorRT-LLM和vLLM開展合作,爲Arctic模型開發初始的推理實現,並且針對批大小爲1的交互式使用進行了優化。
未來,他們還將與社區合作,解決真正大型MoE更大的批大小的推理複雜性。

Cookbook:https://medium.com/snowflake/snowflake-arctic-cookbook-series-exploring-mixture-of-experts-moe-c7d6b8f14d16
另外,Arctic現使用的是4k上下文窗口進行訓練,研究人員還將開發一種基于注意力下沉(attention-sinks)的滑動窗口的方法,以支持未來幾周無限序列生成能力。
下一步,將會擴展到32K上下文窗口。
團隊介紹
Snowflake的CEO,是Sridhar Ramaswamy,是前谷歌高級副總裁。

在谷歌工作15年後,他成爲Neeva的聯合創始人,後來Neeva被Snowflake收購。



他在印度理工學院馬德拉斯分校獲得計算機學士學位,並在布朗大學獲得計算機博士學位。

AI團隊的一把手Vivek Raghunathan,也是前谷歌副總裁。

他曾擔任微軟研究員,後在谷歌從事機器學習、廣告基礎架構等方面工作,18年開始在谷歌擔任副總裁,領導YouTube團隊。
隨後,他和Sridhar Ramaswamy共同創辦了Neeva。


Raghunathan同樣也是印度理工學院的校友,不過是在孟買分校獲得的學士學位。之後,他在UIUC取得了碩士和博士學位。

爲了發展AI,兩人把DeepSpeed團隊最頂尖的幾個元老都挖了過來,包括Zhewei Yao和Yuxiong He。
Zhewei Yao在UC伯克利獲得博士學位,研究興趣在于計算統計、優化和機器學習。(在此之前,他2016年曾獲得上交大數學學士學位。)

他從2021年開始便加入了微軟,在微軟擔任首席研究員和研發經理,致力于高效的大規模訓練和推理。
目前,他是Snowflake的高級科學家和SDE II,同時也是Snowflake大規模預訓練創始成員。
Yuxiong He在微軟任職13年,是DeepSpeed的創始人之一,最近加入了Snowflake。
她曾在新加坡南陽理工大學獲得了計算機工程學士學位。
團隊的另一位華人大牛Aurick Qiao,去年11月剛加入Snowflake。

CMU讀博期間,他曾獲得Osdi 2022的最佳論文優勝獎。此前曾在微軟、Dropbox工作。
曾擔任Petuum CEO,以及LMNet的聯合創始人。
Hao Zhang是UCSD的Halıcıoğ數據科學研究所和計算機科學與工程系的助理教授。

他曾獲得了CMU計算機博士學位,師從Eric Xing。在攻讀博士學位期間,他休學一段時間並在ML平台初創公司Petuum工作。
Hao Zhang在2023年聯合創立了LMnet.ai,這家公司于同年11月加入了Snowflake。
他此前還共同創辦了非營利組織LMSYS Org,該組織訓練了此前十分流行的模型Vicuna以及發起和維護目前最重要的大語言模型評測機制:Chatbot Arena。
他本人的研究興趣是機器學習與系統的交叉領域。
參考資料:
https://www.snowflake.com/blog/arctic-open-efficient-foundation-language-models-snowflake/
