編輯:編輯部
【新智元導讀】日日新·商量大模型5.0最近的一波升級,已經震驚到國外科技圈了!實測之後,我們發現:它的推理、數學能力又有了螺旋式上升。周冠宇最近三年比賽的情況、你不知道的F1冷知識,AI數據庫都讓你所見即所得。中國的大模型,已經震驚了外國科技圈。
這不,這幾天商量大模型的更新,直接讓外國網友驚呼:太瘋狂了,中國的AI界究竟還有多少我們不知道的巨變?

不怪這些網友太大驚小怪——最近全新升級的日日新·商量大模型5.0(SenseChat V5),在基礎能力上再次重大更新,直接把大模型能力升級到新的階段,直觀印象可感的那種。
簡單來就是,這款擁有強大邏輯推理能力的6000億參數MoE模型,可以輕松地把你變成一個更好的打工人。


打工神器Part 1:辦公小浣熊
所以說了這麽多,得到日日新5.0加持的産品,到底會有怎樣非一般的體驗?
首先,我們來看看最直擊打工人痛點的「辦公小浣熊」。
顧名思義,它主打的就是一個辦公能力。

體驗地址:https://raccoon.sensetime.com/office
衆所周知,在真實的辦公場景中,往往會有很多極其複雜的圖表,就連我們人類自己看到都會暈頭轉向。
更何況還有不少資料只有外文的,更是增加了閱讀障礙。

辦公小浣熊可以hold住嗎?
前兩天,F1中國大獎賽剛剛落幕,而作爲索伯技術合作方的商湯,更是提供了一些資料。
而我們也借此直接上了點難度:導入一份擁有60萬條數據的「全英文」表格,涵蓋F1曆史各類數據信息,讓它分析一下。

毫不誇張地說,這項測試非常難!
要知道,這份數據體量非常龐大。而且數據庫中除了英文,還包含簡寫、劃線-等複雜的元素。
比如,「周冠宇」對應的是「guanyu-zhou」(甚至不是guanyu zhou),信息模糊度比較高。
因此,對于模型來說,分析這樣的數據並非是一件易事。
而我們也對這次的挑戰,充滿期待。

順便說一嘴,商湯從2022年周冠宇第一次登上F1賽場開始,連續三年都是車隊的技術合作夥伴
接下來,考驗真本事的時候到了,我們給辦公小浣熊下發任務:
給出周冠宇在2020-2024之間參與比賽數量的柱狀圖。
果不其然,在第一次嘗試時,辦公小浣熊無法從表中的英文名字「guanyu-zhou」匹配到周冠宇。
因此,它會認爲圖中沒有周冠宇的信息。

下一步就得上點「提示」技巧了。
在接下來互動中,和它說「肯定會有的,你再找找」。

通過一步步的引導和互動,模型在我們的引導下學會了反思,然後成功地完成了任務!
可以看到,辦公小浣熊通過努力思考,完成了所給任務的數據分析,並給出了相應的Python代碼。

而這個交互過程也告訴我們,如果給模型的數據表格並不匹配、比較模糊,模型表現不盡如人意時,也不要放棄。通過互動,模型就很可能給我們驚喜,給出不一樣的數據交互體驗。
下面就是一個更難的任務,我們把F1曆史上所有車手、車隊、比賽、賽道、引擎制造商等等信息,導入數據庫文件中,這個數據量是非常龐大的。
然後問模型:F1當中總共有多少車手?可以交叉表格進行計算。
這個任務,同樣難度非常大,因爲在所有字段中,沒有任何一個是中文的。

最終,辦公小浣熊用模糊的匹配,找到了相對應的信息——901位車手,這個答案完全正確!
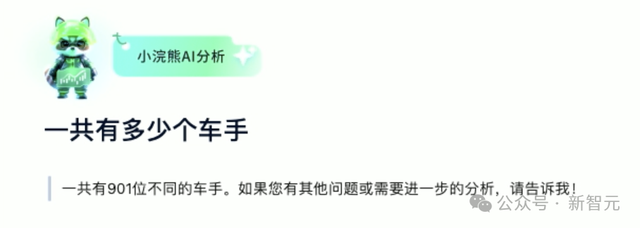
在大模型産品中,辦公小浣熊的這個表現,堪稱高手中的高手。
在這個過程中,模型正是通過交互模式叠代的邏輯,多次查詢了不同的表頭,最終給出了能讓我們理解的信息。
再換一個問題,「有哪些車手獲得總冠軍?並按獲獎次數從高到低繪制柱狀圖」。
最終,模型整理出:獲得最多總冠軍的車手是漢密爾頓和舒馬赫。
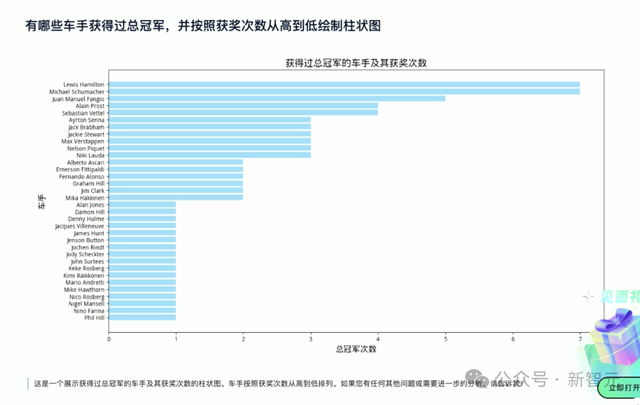
接下來,我們來看看它能不能從不同維度,統計出漢密爾頓和舒馬赫的獲獎情況。
辦公小浣熊畫了一個雷達圖,清晰呈現出兩人杆位數、圈數、領獎台數、勝利數等各維度的能力,漢密爾頓的次數還是略高于舒馬赫。

在這個真實的數據應用場景中,通過交互方式對複雜表格實現了聯動,日日新5.0表現出的強大推理能力,令人印象著實深刻。
下面,再來一個同樣高難度的市場采購的案例。
上傳「2024年新增供應商相關信息」文檔之後,要求它整合到一個表格中,並要求表頭以列出供應商分類、供應商名稱、産品名稱...列出。
辦公小浣熊立刻給出了一個完整、清晰的表格總結版。
甚至,它還可以爲你生成一個可視化的柱狀圖,將IT類、固資類、營銷類、行政類費用直觀地呈現出來。

包括熱力圖這類圖表生成,它也可以拿捏。

此外,我們還可以一並上傳多個文檔,讓辦公小浣熊繼續完成要求的任務。
首先它給出了可查閱的代碼,最後生成了不同類別需要采購的數據表格,一看即明了。

一通測試下來,小編的感慨就是:能用上如此高效的數據分析、總結辦公神器,真是每位打工人的福音。
並且,它還是免費的!

打工神器Part 2:文檔大模型
另一個鮮明體現出日日新5.0能力的産品,就是商量-文檔大模型。
據說,除了表格數據分析外,在長文本處理這個場景下,模型的能力也是一絕。
那我們就要來上難度了:丟給它一堆數學試卷,要求它從中找出一道解一元一次方程的解答題。
很快,它不僅從「小學數學試卷」的第五部分找到了對應的題型,甚至還麻溜地給出了解題過程。

我們還可以對它要求,再幫忙出一道類似的題目,但題型得是選擇題。
它不光給出了題幹,還順便給出了正確答案和解題步驟。

再比如,上傳一份小學試卷,讓文檔大模型幫你以小學生的理解力,去分析其中的一道應用題。

它可以像一位耐心的老師,指導學生做題一樣,從步驟1、2、3詳細地分析了缜密的解題過程,並給出了答案。
這樣的AI老師,有誰不愛?


然後,文檔大模型還可以是「出題機」,能給出一道類似的題目,可以充分鍛煉自己舉一反三的能力。

你還可以將自己做完試題的結果,告訴它,讓它爲你打分。
顯然,8.4 ÷ 0.4 = 2.1答案不正確,正解應該是21。

就著這個文檔,你可以無限提問。
文檔大模型在題目幾乎糊在一塊兒的頁面中,不僅能准確識別你想要的題目,還能悉心給出解答。


給它上傳一份唐詩三百首和宋詞三百首,我們就可以根據這些文件提問了!
比如,找出描寫月亮的詩詞。
它迅速找出了《靜夜思》《望月懷遠》《水調歌頭.丙辰中秋》等作品。

下面,我們還可以來一個拔高性的提問:月亮在唐詩和宋詞中的內涵有哪些異同點?
它回答道:相同點在于都是情感寄托、時光流轉的象征和美的象征,不同點就在于表現手法、情感深度和文化背景的不同。

要問小編每天起早貪黑地辛苦打工,最愛聽到的詞是啥?大家異口同聲的三個字就是——
10W+!

10w+的文章,到底有哪些套路呢?讓文檔大模型幫我們來分析一下。
以下是五篇10w+公衆號爆款文章(沒錯,看名字就知道了)。

讓我們把它們一次性扔給文檔大模型。首先,它可以幫我們總結出每篇文章的摘要。

互聯網文章千千萬,爲什麽偏偏是它們成了爆款?
文檔大模型分析後總結道:貼近生活的真實故事,一下子就讓讀者找到了自己的影子,産生了強烈的情感連接。

挖掘出人類共通的情感體驗,再提供不同的觀察視角,就會讓文章有較高的思考價值。

所以,根據上述經驗,我們如何炮制出類似的爆款呢?文檔大模型提供了以下思路——
疫情下的親子關系新常態;遠程工作時代的職場媽媽;數字斷舍離;老錢風到新錢風;人工智能時代的職業轉型之路……

好家夥,這些命題聽起來個個都很吸睛,已經忍不住想看了!下一步,就是碼出幾千字,篇篇十萬加,走上人生巅峰了。
文檔大模型這種超強的文本分析能力,甚至可以爲文史哲的同學們寫嚴肅論文提供思路。
比如,《論語》和《道德經》關于「德」的觀點,有何異同?
文檔大模型在咀嚼了長達29頁21638個字的《論語》和14頁7302個字的《道德經》後,分析出——
相同點在于,二者都高度重視「德」在個人修養和社會治理中的作用;區別在于,《論語》中的「德」更多關聯到個人,後者還涉及到順應自然、無爲而治的理念。

如果想深入研究,應該閱讀那些參考文章和書籍?文檔大模型列出了相關領域的經典著作。

更厲害的來了,如果把兩個文檔的思想整合,能得到怎樣的啓發呢?文檔大模型表示,可以從和諧共生的生活哲學、內在修養與外在行爲的統一等方面入手。
沿著這個思路深入探討下去,或許就能肝出一篇觀點別具一格的學術論文了。

一大波Benchmark襲來
當然,除了打工之外,對于各種刁鑽的測試,日日新5.0也沒在怕的。
首先我們來看一張新鮮出爐的小米SU7照片。
因爲是隨手抓拍的,車輛本體其實很小。
不過,在日日新5.0加持下的商量,很輕松地就識別出了車型,而且還附上了一波詳細的介紹,非常專業。


相比之下,其他的模型就直接GG了。
要麽是認錯了車,要麽連車都沒看到,只識別出了照片的水印。


接下來,向我們走來的,就是日日新5.0大戰「弱智吧」難題。

「只切一刀,如何把四個橘子平均分給四個小朋友?」
商量爲了公平起見,只切一刀還是得將四個橘子排成一排。這樣,一刀下去,每個小朋友還是一人一個橘子。

這招真是高明!

接下來,則是一道非常「正經」的推理題。
「一個獵人向南走了一英裏,再向東走了一英裏,然後向北走了一英裏,最終回到了出發點。他看到一只熊並開槍打死了它。這只熊是什麽顔色」?
商量一語中的,說出了這道題實際上是——地理謎語。

因爲只有在極點的時候,獵人才能聽起來這麽曲折的路程,回到出發點。
也就是說,這只熊一定是北極熊了。

5次模型叠代,全面對標GPT-4 Turbo
一波測試下來,想必你也對升級後的日日新5.0能力,有了大概的了解。
下圖是一張對行業裏模型的橫評。
注意看,圖中有一個亮點:最近的行業模型叠代,在純粹知識型能力上提升沒有那麽顯著,但在高階推理,尤其是數學能力上,有了很大提升。
比如,GPT-3.5到GPT-4的提升有100%之多,而Llama 2到Llama 3,直接提升了400%之多。
這是因爲,大部分用來提升數據質量的能力都構建在了推理能力上,並且是合成數據的推理。
尤其對于領域應用的落地而言,高階推理能力更是成了行業大模型能力推進的重要指標。
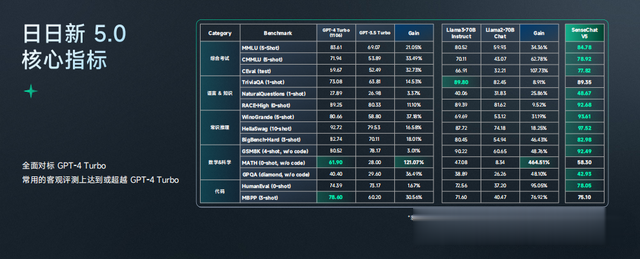
日日新5.0在大部分核心測試集指標上,都已對標甚至超過了GPT-4 Turbo
讓我們重回到這些評測上,不難看出,日日新5.0在語言、知識、推理、數學、代碼等能力上,都有了一波明顯的。
而在主流客觀評測上,它已經達到甚至超越了GPT-4 Turbo的水平!
正如前文所說,日日新5.0如此之強的能力,靠的就是商湯團隊在模型架構,以及數據配方上的持續優化。
從日日新1.0、到2.0、3.0、4.0,以及今天5.0的發布,每一次版本重大的叠代,背後核心都是——數據的升級。
過去一年裏,商湯花了大量時間去完成了語料質量的優化,搭建了完善的數據清洗的鏈條。
對于5.0版本,他們重點關注了數據集中,是否蘊含比較豐富的邏輯。
通過對有高信息密度,邏輯性強的語料給予更高的權重,並對整體語料進行了高質量清洗,從而實現性能提升。
具體來說,商湯在知識層面上,采用了超10T的Token,保證了LLM對客觀知識和世界的初級認知。
除此以外,商湯還合成了數千億的思維鏈數據,成爲日日新5.0性能提升,對標GPT-4 Turbo的關鍵。x
在內部,合成數據方式經曆了兩次叠代,從最初用GPT-4來合成數據,過渡到用自己模型中間版本合成數據,再進行訓練的過程。
其中,商湯90%的合成數據是自家模型生成的,另外10%的數據由世界頂尖LLM生成。
由此,便可以得到非常高質量的數千億合成數據。

這幾天,奧特曼在斯坦福閉門演講中談到,「Scaling Law依舊有效,GPT-5要比GPT-4更強大,GPT-6也遠遠超越GPT-5,我們還沒有到達這條曲線的頂端」。
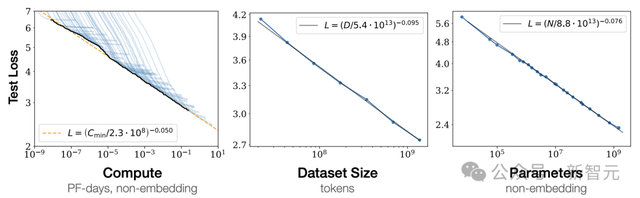
也就是說,大模型下一步發展的空間潛力,將是無窮無盡的。
還真是有點期待日日新6.0的誕生了。
參考資料:
https://chat.sensetime.com/
