編輯:編輯部
【新智元導讀】在今天的2024中關村論壇年會「人工智能主題日」上,可謂精彩紛呈,亮點頻出。清華團隊發布了最接近Sora的Vidu視頻大模型,驚豔的demo令現場觀衆連連驚呼。北大教授、中科院院士鄂維南和中國工程院院士、中國人工智能學會理事長戴瓊海等的演講,則將論壇推向了無比專業的高度。
中關村論壇舉辦以來的首個主題日活動:「人工智能主題日」今日開啓!
到場嘉賓,也是星光熠熠,大佬雲集,還有著濃濃的國際範兒,與世界頂尖水平接軌。
一共161位嘉賓,近一半是外籍AI大佬和從業者。
而嘉賓陣容也是非常豪華,彙集了國內外30多名院士,還有諾獎、圖靈獎得主,清北港科大等知名高校的校長副校長。
百度、螞蟻、微軟、亞馬遜等世界領軍科技企業,也都前來參會。
可以說,「人工智能主題日」堪稱如今AI界的頂級盛會,亮點滿滿,精彩紛呈。
重磅技術成果發布
國産Sora,又上新了!
在今天的中關村論壇「人工智能主題日」上,生數科技聯合清華大學,共同發布了最新的視頻大模型「Vidu」。
Vidu生成的畫面一亮相,就讓全場驚呼——這個效果也太像Sora了!

在人物和場景時間一致性的保持上,Vidu的表現令人印象深刻。

而且,它生成的視頻最長可達16秒左右,在時長上破了紀錄。
甫一亮相,Vidu就得到了業內公認——
綜合考慮時長、一致性、真實度、美觀性等因素,它是「國産Sora」模型中當之無愧的佼佼者,是國內最能和Sora全面對標的視頻模型。
清華大學人工智能研究院副院長、生數科技首席科學家朱軍爲我們放出了Vidu的以下演示。
一只小狗在遊泳池裏遊泳,毛發纖毫畢現,狗腳劃水的動作十分自然,和水的相互作用十分符合物理學原理。

人物眼睛的特寫、做陶罐的女人手中正在轉動的陶罐、一對坐著的男女同時擡頭的動作,都刻畫地細致入微,逼真到仿佛現實。

總的來說,Vidu具有以下幾大特點——
模擬真實物理世界森林裏的湖邊風光,無論是樹、水面、雲朵,還是整體的光影效果,很逼真寫實。

汽車行駛在崎岖山路上的場景,也是非常經典的Sora演示。
Vidu模擬了非常真實的光影效果,連揚起的灰塵,都十分符合物理規律。
 富有想象力
富有想象力在這艘AI視頻模型必考題中,Vidu生成的視頻效果實在太驚豔!
畫室裏的一艘船駛向鏡頭的場景。

這道題,考驗了模型虛構場景的能力,爲了生成超現實主義的畫面,它們需要具有超強的想象力。
理解多鏡頭語言可以看出,Vidu能夠理解多鏡頭的語言,不再是簡單的鏡頭推拉。這樣,就能模擬我們的攝影過程。
生成的這個視頻中,要求它包含海邊小屋、鏡頭過渡到陽台、俯瞰大海、帆船、雲朵等元素。
Vidu生成的視頻,具有複雜的動態鏡頭,遠、近、中景、特寫,以及長鏡頭、追焦等效果,都十分驚豔。
 一鏡到底,16s時長
一鏡到底,16s時長而在這個視頻中,Vidu展現出了16s的超長「一鏡到底」。
而且,視頻完全是由單一大模型生成的,不需要任何插幀、剪切,直接就實現了端到端的生成。
 超強時空一致性
超強時空一致性要求它以《戴珍珠耳環的少女》爲靈感,生成一只藍眼睛的橙色貓,可以看出,Vidu生成了連貫的視頻。
從旋轉的各個視角看,都非常逼真,甚至讓人産生了「這是一個3D模型」的錯覺。

它生成的視頻中,人物和場景在時空中始終保持一致。
理解中國元素相比國外的AI視頻模型,Vidu也更理解中國元素。
熊貓、龍這樣的中國元素,它都能理解和生成。

和Pika、Gen-2比起來,Vidu的表現也絲毫不弱。
一艘木頭玩具船在地毯上航行。
兩位對手的視頻一個只有4s,一個更是畫面簡單的循環播放,而Vidu的視頻以16s的自然畫面秒殺了它們,在一致性的保持和語義理解上,也都非常突出。
用和Sora同樣的prompt,Vidu的表現甚至更好。
Sora並未理解旋轉的鏡頭是什麽意思,而Vidu不僅表現出了旋轉,還保持了一致性的效果。

幾分鍾的視頻結束,全場響起經久不息的掌聲。
之所以能在短時間做出如此驚豔的視頻AI模型,離不開團隊的長期積累和多項原創成果。
團隊的技術路線,竟也和Sora的高度一致。
 全球首個低碳、高性能多語言LLM
全球首個低碳、高性能多語言LLM此外,全球首個低碳、高性能、低幻覺多語言大模型Tele-FLM,由北京智源人工智能研究院與中國電信人工智能研究院(TeleAI)在今天正式聯合發布——所有核心技術、權重、訓練過程中的各種細節全面開源。
520億參數的Tele-FLM在2T token的數據上,用時2個月完成訓練。

值得一提的是,據Meta3官網信息,Llama 3-70B模型的訓練,可能使用了近5萬塊H100。而Tele-FLM僅用了896×A800的算力,完成了訓練。
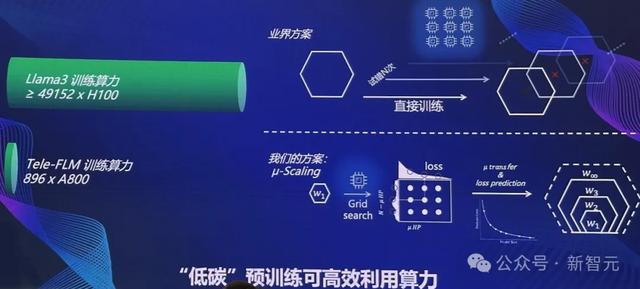
此外,模型訓練過程還對數據質量進行嚴格把控。
通過使用高質量的中文數據,雖然只占30%,但Tele-FLM的中文能力明顯超越了對標的模型,取得了領先的成果。

未來,還將推出千億、六千億、甚至萬億參數版本,而且都將全部開源,供所有人使用。

順便提一句,會上最精彩的部分,莫過于機器人上台表演了。
看看來自宇樹科技的這只機器狗,倒立行走,簡直太飒了。

除了頗有前沿範兒的技術成果發布,人工智能主題日上,國內大佬的演講也是幹貨滿滿。
大佬演講精彩亮點
北大教授、中科院院士鄂維南的演講,讓我們重新審視,大模型+大數據庫相結合的價值所在。
如今,我們能夠暢想人工智能的未來,那都是因爲有一個最基本的工具——深度學習。
其實,深度學習很早就誕生了。
但真正將其帶向世界,釋放出重大威力的標志性事件便是——2012年,Hinton和兩位學生訓練的大型深度神經網絡一舉贏得ImageNet大賽。

每個人都知道,若想開展機器學習研究,需要有三個最基本的工具:
一是模型工具,借助諸如Pytorch、TensorFlow、MindSpore等工具,AI開發者才能寫出深度神經網絡。
二是算力工具,當然非GPU莫屬,再結合CUDA這樣的架構,實現高效的算力利用率。
三是數據工具。

現在,全世界包括OpenAI、谷歌等在內的公司,都希望獲取高質量的數據。同時,數據稀缺已然成爲LLM訓練的一大難題。
也正是在數據這個領域,現在的發展還不是很成熟,缺少可以利用的工具。
對于數據的處理,大家還是主要憑經驗,沒有一個完整的系統,去解決這一問題。
其中,「非結構化數據」處理,是機器學習方法的主要困難之一。
如果我們可以將文本、視頻之類的數據,能夠將其放在一個表格當中,那將會大大降低ML門檻。
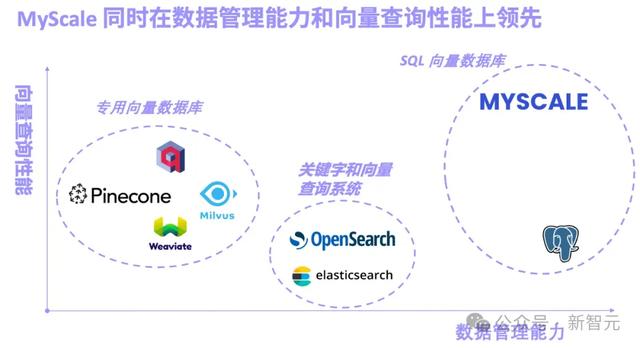
就在這個月初,國際上第一個AI「非結構化數據庫」MyScale正式宣布開源。
通過自研高性能和高數據密度的向量索引算法,成爲目前綜合性能最好,功能最強的AI數據庫。
 LLM+大數據雙輪驅動
LLM+大數據雙輪驅動那麽,現在有了如上這些能力,接下來可以做什麽?
或者說,下一個技術路線是什麽?

當我們將所有數據放在「數據庫」中,基于此,就可以構建各種各樣的小模型,由此産生了「模型庫」。
最後,就可以通過操作系統對模型進行調度。
這樣的優勢在于,不僅可以將所有結構化數據,以及非結構化數據,放在同一個數據庫中,還能通過常見的SQL語言實現搜索查詢。
此外,還可以很高效地訓練出小樣本的數據模型。與訓大模型不同,訓練小模型,如何選取數據是非常困難的。
比如針對自動駕駛場景,無用樣本只會影響模型的效率和精度問題。
有了AI數據庫,就可以快速獲取相應的樣本數據,比如紅燈、左轉彎等。
由此一來,訓練後的自動駕駛模型,准確率可以提升50%-90%。

除此以外,模型管理平台,可以提供對模型全周期的管理。

一個很典型的場景是——政府智慧城市管理,以前遇到的是數據孤島的難題,到現在的模型孤島。
每個企業基于不同的模型做一個應用,由此帶來的問題是,正度很難實現全面、方便快捷的管理。
而雲平台的出現,可以讓企業基于此做低門檻的開發,根據需求即可調用成千上萬的模型。
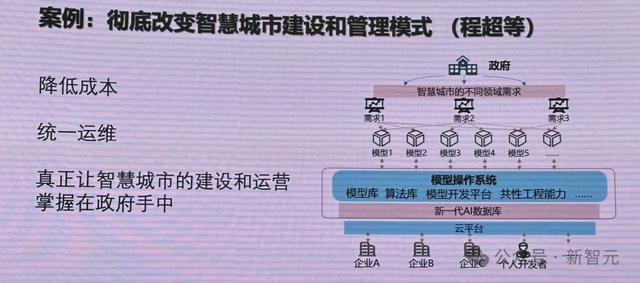
而現在,大模型誕生可以大大提升基礎AI能力,還有可以實現具體任務的Agent。
接下來,就可以在原來框架下稍作改動:
- 小模型改成Agent
- 模型生産平台以預訓練模型作爲基座

另一方面,模型操作系統可以將模型和任務完成對接。
比如,把政府的需求梳理後,針對每個需求去做一個模型,結果就會産生很多模型。甚至一個需求,需要做不同的模型。
然而,針對複雜場景,模型操作系統卻很難將模型和任務完成對接。
鄂維南院士表示,「這恰恰是未來大模型能夠提供的真正的核心能力——一個能完全將模型和任務匹配的操作系統」。
另外,大模型還可以和大數據庫進行結合。

比如,鄂維南院士預告的團隊成果——Science Navigator平台。
它是將所有理工科的文獻塞到一個數據庫裏,由此訓出的文獻大模型,具備了查詢文獻、提供論文寫作靈感等能力。
未來,還可設想將國家圖書館所有資料塞進數據庫中,讓模型釋放出更大的潛力。
總而言之,想要訓出優質大模型,構建一個高效的數據處理的系統,是關鍵所在。
 光電智能計算登上Nature
光電智能計算登上Nature接下來,是中國工程院院士、中國人工智能學會理事長戴瓊海對于光電智能計算方面的介紹。
要說大模型再發展下去,面臨的最大危機是什麽?
大家都知道,答案無疑就是算力和電力的巨大缺口了。
如今,GPT系列的研究,已經累計投入了超過30億美元。

AI模型的耗電,實在是太猛了!
ChatGPT每天的能耗高達70萬美元,而在十年內,大模型計算將消耗我國每年發電量的5%到10%!

黃仁勳、Sam Altman、馬斯克等大佬,也都紛紛預言:下一波AI消耗的電力將遠遠超過預期,能源系統難以應對。超級AI,將成電力需求的無底洞!

如今的主流通用芯片就是GPU,此外還有延長線,即專用芯片,這些都是基于電子電路的發展。

而第三條路,就是新型的計算架構,比如量子計算、存算一體、光電計算。
能否從電子電路,改變成光的載體?1966年,「光纖之父」高锟打開了光通信的大門。

不過有一個問題是:功耗下來了,算力卻一直提不上去。
爲此,我國在國際上第一個提出了一個,大規模可重構衍射計算處理器(DPU)。

在架構突破上,我國團隊首次提出了光-電-光融合可重構計算方法;在非線性突破上,首次提出了光電探測非線性激活函數。

光電之間的ADDA轉換,要花費巨大的功耗,這就是一個最重要的瓶頸。

在此基礎上,團隊提出了光電混合全模擬的智能計算架構,研制了ACCEL芯片,突破了光電模數的轉換瓶頸,直接讓系統級能效提升了百萬倍!
這項研究去年已在Nature上發表,同樣屬于中關村創新成果。

如今,ACCEL芯片已經在很多任務級開展了工作,讓能耗大大下降。

相比英偉達A100,ACCEL芯片讓系統級算力提升了3個數量級,能效提升了6個數量級。
在國際上的整個光芯片領域,都處在最前沿。

不過,真正的大模型訓練和推理,還是存在一個關鍵的問題:深度網絡做不了深,層數就非常有限。
于是,團隊又提出了一個新的架構——大規模智能光計算芯片「太極」。
電子的深度網絡架構可以做一百層、兩百層,但光卻做不了深,怎麽辦?
團隊的辦法是,化「深」爲「廣」,其中有幹涉也有衍射,用幹涉來做廣,用衍射來做深,這就把以前的深度架構改成了拉伸的架構。
橫縱結合,是爲太極。

兩種光性質結合在了一起,就建立了任務編碼宏觀拆分機制。具有「廣度」的光神經網絡,就能支撐複雜的智能任務。

甚至能做100多層的深度網絡。
而下圖中的藍色線條,即爲衍射。幹涉和衍射,就像樂高拼玩具一樣,拼在一起,就可以做大模型的光計算應用。
大規模的太極光計算芯片,完全可以支持現在的圖像分類、多種音樂風格的生成。

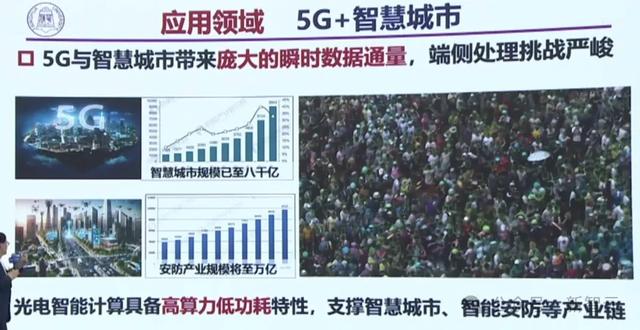
在未來5G和智慧城市結合,會帶來龐大的瞬時數據通道,讓端側處理面臨著嚴峻挑戰。
比如下面這個超大的視頻,如果由A100來跑,還需要8台到10台以上才可以。而光芯片只需要一台,就可以進行這方面的應用了。
因此,光電智能計算,可以支撐智慧城市、智能安防等産業鏈。
未來, 團隊還計劃構建一個光算力實驗室,總之,太極芯片非常有望實現工業場景的應用。
海澱區優勢聚集
以上重磅成果,恰好都誕生在海澱。爲什麽?
仔細分析可以知道,這種現象是一種必然。
人才+生態在海澱,彙集了高密度的人才和生態土壤。
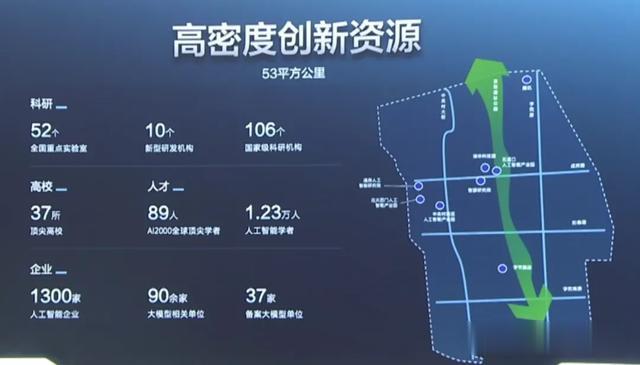
要說海澱區的AI人才濃度,說一聲全國TOP 1應該不算過分。
在這裏,彙聚起了1.23萬人工智能學者,和89位AI2000全球頂尖學者。
全國AI人才看北京,北京AI人才看海澱。
已經「出廠」的人才,密密麻麻地分布在海澱的近千家企業。海澱的AI企業,直接占全北京的2/3,全國的1/5。
還在校的人才,也正緊鑼密鼓地培養中。
全海澱的37所高校中,設立AI專業的高校,就高達21所。
人才、企業、算力基礎設施布置,海澱是妥妥的一條龍布局。
說一聲AI建設創新策源地和産業高地,海澱區是當之無愧。
從小學就開始了AI人才從什麽時候開始培養?在海澱區,答案是小學生。
海澱區教育委員會,在海澱區的中小學內,正在建設「大模型+教育」場景。
爲此智源研究院構建了一套基礎教育專屬知識庫,爲小學的3個學科、中學的6個學科,提供了2000套試題。
在學校,孩子們不僅有人工老師,還有AI老師。
海澱區的小學生和中學生們,在課余時間可以隨時向AI老師提問。各種學段、各種學科,AI老師都能爲孩子們提供一對一精講答疑。
縱觀全區,已經有36所學校的近3萬名學生,用上了AI産品。
作爲全區AI教育的先鋒,中關村三小已經基于多種大模型平台,構建出本校的模型對接平台了!
在這個平台上,設定好了學校專用的「知識庫」,可以對接不同的模型引擎,分析知識庫內容,做相應的輸出。
目前,中關村三小的小學生們,已經擁有了自己的「小學信息科技課標助手」「小學語文學科課標助手」「六年級下冊」專用模型了!

海澱名校北京一零一中學,也和北京大學前沿計算中心、騰訊公司合作建立了人工智能AI實驗室。
在實踐的探索中,幾方聯合構建出了三級人工智能實驗室課程體系,包括人工智能校本課程、大中貫通課程、校企聯合課程。
另一名校十一學校,則直接組建了一支AGI應用研究項目團隊。
在這裏,老師們會使用智譜清言和Kimi Chat等國産大模型,來加持自己的教學設計國産,文章、報告、教案的生成,都比以往快了不少倍。
 高校雲集,精英彙聚
高校雲集,精英彙聚連中小學都已經用AI工具全面「武裝」,那就更不用說,位于海澱的清華、北大、北航、人大、北大、北理工等響當當的全國頂級高校了。
強強聯合,會碰撞出怎樣的火花?
在高校層面,海澱區政府已經率先打通了多項深度合作。
和清華,海澱區簽訂了「共建人工智能産業高地」戰略合作協議。
這項深入合作,將圍繞AI創新平台建設、核心技術攻關、科技成果轉化等多方面,共同整合雙方資源。

其次,海澱區與北航簽署了合作備忘錄,共建AI産業高地。
未來,雙方還會在促進科教融合發展、推動産業規模集聚、深化人才培養與交流、優化人文環境建設等方面,開展深入合作。

同時,海澱區還與人大簽署了共建人工智能産業高地合作備忘錄,在人工智能理論研究、技術協同攻關、高端智庫建設、人才培養等方面緊密對接,加速科研成果轉化落地,推動人工智能健康發展,全力建設好中關村人工智能産業集聚區。

最後,海澱區會繼續與北郵、北大、北理工等高校,在核心技術攻關、人才交流培養、産業集聚發展、科技成果轉化等領域展開深入合作,加快形成新質生産力。
AI産業高地,已然在逐漸建成。
全國重點實驗室落地與此同時,海澱區服務落地了多個人工智能領域全國重點實驗室。
海澱區積極對接全國重點實驗室,重點落地建設清華大學互聯網體系結構室、北京大學微納電子器件與集成技術等人工智能領域相關全國重點實驗室,加強區域共建,推動優勢學科向縱深突破。

深度對接區內人工智能領域全國重點實驗室,服務支持全重發展建設,推動優質科技成果落地海澱。
科技成果轉化平台如何讓高校成果走向實驗室?如何讓AI技術更好地服務企業和社會?
爲了打通科技成果轉化「最初一公裏」,概念驗證中心如雨後春筍般破土而出。
而當前,已有的清華、中科院等5家概念驗證中心,已經踏出了成果轉化的「第一步」。
此外,海澱區還正在籌建AI領域概念驗證中心。
未來,還會有更多的科研成果在海澱區完成應用轉化,隨著産業聚集,這裏將出現一片別樣的創新生態。
