報告出品方:中信建投
以下爲報告原文節選
------
一、國內 AI 産業有望迎來跨越式發展
1.1 海外 AI 産業蓬勃發展
OpenAI 于 2023 年 3 月發布 GPT-4,谷歌于 2023 年 12 月發布 Gemini 大模型,並在近期推出 Gemini1.5 pro以及開源模型 Gemma,大模型能力持續叠代升級。伴隨大模型能力的提升,海外 AI 應用蓬勃發展,雲大廠比如微軟推出 copilot、bing AI 等,谷歌推出 workspece、聊天機器人 Gemini 等外,B 端垂直企業服務、C 端應用等層出不窮。據 SensorTower 數據顯示,2023 年,AI 應用年度下載量和內購收入分別上漲 60%和 70%,超過21 億次和 17 億美元(其中 2023H1 下載量突破 3 億次)。英偉達提到,FY24 全年估計 40%收入來自 AI 推理端。
近期 openai sora、谷歌 Genie 發布,視頻應用領域 AI 能力邊界大幅躍升,AI 向基礎世界模型、AGI 領域邁進。

從支撐 AI 發展的基礎設施角度,不管是從英偉達、超微電腦、台積電、AMD 等硬件廠商的業績和指引,還是從海外雲廠商的 capex 投入,都印證海外 AI 産業的持續提速。
英偉達 FY24Q3、FY24Q4 業績持續超過分析師預期,主要來自 AI 帶動數據中心業務超預期帶動,英偉達對下一季度指引樂觀,預計 FY25Q1 收入 240 億美元,同樣超過分析師預期的 219 億美元。超微電腦 FY24Q2營收超預期,FY24Q3 預計淨銷售額在 37 億美元至 41 億美元之間,遠超市場預期,主要得益于 AI 系統強勁需求的驅動。台積電預計未來幾年 AI 相關業務 CAGR 將達 50%,上調遠期 AI 營收占比目標,預期 2027 年 AI營收占比達到高雙位數(high teen),此前預期爲低雙位數(low teen)。AMD 在 2023 年 12 月上調加速器規模預測,預計到 2027 年,人工智能加速器的整體市場規模將達 4000 億美元,CAGR 達到 70%,此前 2023年 8 月 AMD 預計 2027 年人工加速器行業規模爲 1500 億美元。
海外雲廠商對 AI 投入展望持續樂觀。谷歌指引 2024 年資本支出將明顯增長。meta 指引 2024 年資本開支300 億美元-370 億美元,上限上調 20 億美元。微軟表示,基于對雲和人工智能基礎設施的投資、第三方産能合同的交付轉移到下一季度,預計下一季度資本支出將環比大幅增加。亞馬遜預計 2024 年資本支出將同比增加。

1.2 國內大模型基本實現能力邊界突破
國內廠商也加快研發節奏,紛紛發布大模型産品,並不斷持續叠代更新。2023 年 3 月-6 月間,包括百度、清華智譜、阿裏巴巴、科大訊飛、百川智能等廠商相繼發布自己的大模型産品,後續持續叠代更新,在 2023 年9 月、10 月前後發布重要更新,提升模型能力。國內領先的大模型基本在 2023 年 10 月至 11 月實現了能力邊界的突破,實現看齊甚至部分能力超越 ChatGPT,並且後續在持續的進一步叠代升級。隨著國內大模型能力的提升,AI 應用預計 2024 年也將迎來加速落地。

參考國內中文模型評測機構 SuperCLUE 發布中文大模型基准測評,對比來看,國內大模型廠商的能力在快速提升。2023年5月,國內大模型總體與 GPT3.5有約20分的差距,國産得分最高的星火認知大模型總分 53.58,而 GPT3.5 爲 66.18。2023 年 11 月,國産頭部大模型已基本完成對 GPT3.5 的總分超越,與 GPT4-Turbo 的差距也在快速縮小,74.02 分的文心一言 4.0、72.88 分的 Moonshot 等大模型超越了 59.39 分的 GPT3.5,與 89.79 分的 GPT4 仍有距離。SuperCLUE 最新的 2024 年 2 月測評結果顯示,國産第一梯隊大模型已將與 GPT4.0 的得分差距拉至 10 分以內,其中文心一言 4.0 總分 87.75,GLM-4 總分 86.77,通義千問 2.1 總分 85.7、Baichaun3 總分 82.59、Moonshot(kimichat)總分 82.37、訊飛星火 V3.5 總分 81.01,而 GPT4.0-Turbo 總分 92.71、GPT3.5總分 64.34。

近期 Kimi 支持 200 萬字超長文本,用戶數激增,國內模型的能力和應用的展望進一步樂觀。2024 年 3 月18 日,月之暗面宣布 Kimi 智能助手已支持 200 萬字超長無損上下文(2023 年 10 月剛發布時,Kimi 可支持的無損上下文輸入長度爲 20 萬字),在長文本處理能力上取得了突破性進展,並于即日起開啓産品內測。Kimi的月活用戶從 2023 年底的 50 萬左右增至接近 300 萬,網頁端的日活從 3 月 9 日的 12 萬多增至 14 日的 35 萬左右,3 月 21 日,Kimi 因訪問量暴增而疑似宕機。
1.3 國家大力推動 AI 建設與應用落地
2024 年 2 月 19 日,國務院國資委召開中央企業人工智能專題推進會。會議認爲,加快推動人工智能發展,是國資央企發揮功能使命,搶抓戰略機遇,培育新質生産力,推進高質量發展的必然要求。中央企業要主動擁抱人工智能帶來的深刻變革,把加快發展新一代人工智能擺在更加突出的位置,不斷強化創新策略、應用示範和人才聚集,著力打造人工智能産業集群,發揮需求規模大、産業配套全、應用場景多的優勢,帶頭搶抓人工智能賦能傳統産業,加快構建數據驅動、人機協同、跨界融合、共創分享的智能經濟形態。會議強調,中央企業要把發展人工智能放在全局工作中統籌謀劃,深入推進産業煥新,加快布局和發展人工智能産業。要夯實發展基礎底座,把主要資源集中投入到最需要、最有優勢的領域,加快建設一批智能算力中心,進一步深化開放合作,更好發揮跨央企協同創新平台作用。開展 AI+專項行動,強化需求牽引,加快重點行業賦能,構建一批産業多模態優質數據集,打造從基礎設施、算法工具、智能平台到解決方案的大模型賦能産業生態。10 家頭部中央企業簽訂倡議書,表示將主動向社會開放人工智能應用場景。

二、國産算力基礎設施迎來發展機會
2.1 AI 發展需要強大算力基礎設施支撐
大語言模型所使用的數據量和參數規模呈現“指數級”增長,帶來智能算力需求爆炸式增長。OpenAI 在2018 年推出的 GPT 參數量爲 1.17 億,預訓練數據量約 5GB,而 GPT-3 參數量達 1750 億,預訓練數據量達 45TB,而當前來看,大模型參數進一步提升,已經達到萬億級,並持續叠代發展。訓練階段算力需求與模型參數數量、訓練數據集規模等有關,參考天翼智庫測算信息,根據 OpenAI 發布的論文《Scaling Laws for Neural Language Models》數據,訓練階段算力需求=6×模型參數數量×訓練集規模,GPT-3 模型參數約 1750 億個,預訓練數據量爲 45TB,折合成訓練集約爲 3000 億 tokens,GPT-3 的總算力消耗約爲 3646PFLOPS-day,實際運行中,GPU算力除用于模型訓練,還需處理通信、數據讀寫等任務,對算力會有更大消耗。面向推理側算力需求,參考天翼智庫測算信息,根據 OpenAI 發布的論文《Scaling Laws for Neural Language Models》數據,平均每 1000 個 token對應 750 個單詞,推理階段算力需求=2×模型參數數量×token 數。ChatGPT 上市僅 5 天就突破 100 萬用戶,兩個月內用戶就突破 1 億大關,現在每周活躍用戶維持在億量級。假設按照 1 億的 ChatGPT 的活躍用戶數、日活躍用戶 2000 萬人,平均每位用戶單次查詢對應 1000 個 token,每天查詢 10 次,GPT-3 模型每日對話産生推力算力需求爲 810PFLOPS-day,同樣考慮到有效算力比率,實際運行中需要更大算力支撐。

人工智能的發展將帶動算力規模高速增長,繼而刺激算力基礎設施的需求。根據中國信通院數據,2022 年全球計算設備算力總規模達到 906EFLOPS,預計未來 5 年全球算力規模增速將超 50%。IDC 數據顯示,2022年中國通用算力和智能算力規模分別達 54.5EFLOPS(基于 FP64)和 259.9EFLOPS(基于 FP16),2027 年通用算力和智能算力規模將達到 117.3EFLOPS 和 1117.4EFLOPS,預估未來 5 年複合增長率 16.6%和 33.9%。

運營商加大智能算力基礎設施投入。中國移動 2024 年計劃總體資本開支 1730 億元同比下降 4%,用于算力資本開支計劃 475 億元同比增長 21%。中國電信 2024 年計劃總體資本開支 960 億元同比下降 4%,用于産業數字化資本開支 370 億元同比增長 4%,用于雲/算力投資 180 億元。中國聯通 2024 年計劃總體資本開支 650 億元同比下降 12%,公司表示投資重點將由穩基礎的聯網通信業務轉向高增長的算網數智業務。在相關 AI 服務器采購方面,2023 年 8 月,中國電信啓動 2023-2024 年 AI 算力服務器集采,整體采購規模爲 4175 台,中標總價超84 億元。2023 年 9 月,中國移動啓動了 2023 年至 2024 年新型智算中心(試驗網)采購項目,采購人工智能服務器(2454 台)、數據中心交換機(204 套)及其配套産品等,總價約 33 億元(標包 4-12 總額,標包 1-3 采購失敗)。2024 年 3 月,中國聯通發布 2024 年人工智能服務器集中采購項目資格預審公告,涵蓋人工智能服務器合計 2503 台,關鍵組網設備 RoCE 交換機合計 688 台。同時,三大運營商也在積極加快智算中心等基礎設施的建設。

國內互聯網廠商資本開支呈現回暖態勢。2023年全年騰訊資本開支爲238.93億元,同比增長32.6%,2023Q1、2023Q2、2023Q3、2023Q4 騰訊的資本開支分別爲 44.11、39.35、80.05、75.24 億元,分別同比-36.7%、+31.1%、+236.8%、+33.1%。阿裏巴巴在 2023 年前三季度單季資本開支同比均呈現下滑,2023Q1、2023Q2、2023Q3 阿裏巴巴的資本開支分別爲 25.13、60.07、41.12 億元,分別同比-72.7%、-46.0%、-62.5%,2023Q4 同比轉爲正增長,資本開支爲 72.86 億元,同比增長 25.8%。

英偉達持續升級 GPU,算力持續提升。2024 年 3 月 GTC 上,英偉達發布 GB200 超級芯片,采用 Blackwell架構,采用台積電的 4 納米(4NP)工藝,整合兩個獨立制造的裸晶(Die)形成一個 Blackwell GPU,兩個 Blackwell GPU 與一個 GraceCPU 結合成爲 GB200 superchip。Blackwell GPU 共有 2080 億個晶體管,上一代 H100 只有 800億晶體管,整體性能明顯提升。一個 GB200 NVL72 就最高支持 27 萬億參數的模型。英偉達表示,過去在 90天內訓練一個 1.8 萬億參數的 MoE 架構 GPT 模型,需要 8000 個 Hopper 架構 GPU,15 兆瓦功率,如今同樣給90 天時間,在 Blackwell 架構下只需要 2000 個 GPU,以及 1/4 的能源消耗。
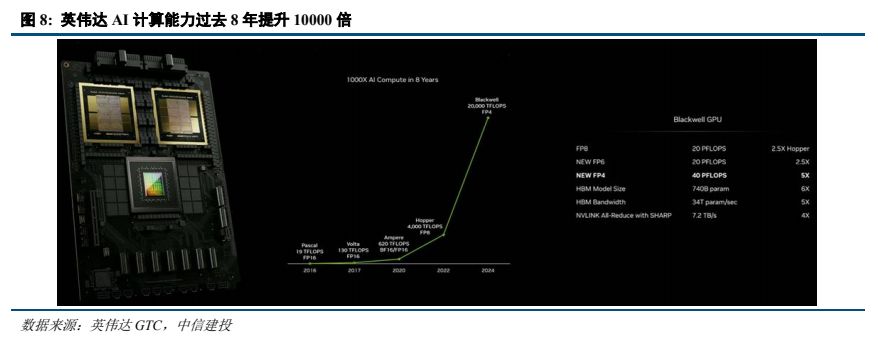
2.2 禁運持續升級,國産化大勢所趨
美國對中國先進芯片進口限制持續升級。2023 年 10 月,美國頒布新的半導體出口限制,對芯片算力和性能密度做了更嚴格的規定,A100/A800、H100/H200/H800、L4、L40s 均不滿足出口條件。在 2022 年 8 月,美國首次針對中國實施大規模芯片出口制裁,停止出口 A100 和 H100 兩款芯片和相應産品組成的系統。本次制裁主要限制總計算性能(算力*位寬)≥4800 且互聯帶寬≥600GB/s 的高端 AI 芯片出口,在制裁後,英偉達爲中國重新設計了 A800 和 H800 兩款“閹割版”芯片,主要在互聯速率和雙精度計算性能上做了限制。2023 年 10月升級版本的芯片禁令加大了打擊力度,性能滿足以下條件均受出口管制:(1)總計算能力 TPP(算力*位寬)超過 4800 的芯片;(2)TPP 超過 1600 且 PD(TPP/芯片面積)超過 5.92 的芯片;(3)2400≤TPP<4800,且 1.6≤PD<5.92的芯片;(4) 1600≤TPP,且 3.2≤PD<5.92 的芯片。在此要求下,A100/A800、H100/H200/H800、L4、L40s 均不滿足出口條件,英偉達只能全方位削弱芯片算力,向中國提供 H20、L20、L2 芯片。而近日美國政府再次升級對華半導體出口管制措施。參考钛媒體信息,北京時間 2024 年 3 月 30 日淩晨,美國商務部下屬的工業與安全局(BIS)發布“實施額外出口管制”的新規措施,修訂了 BIS 于 2022、2023 年 10 月制定的兩次出口限制新規,全面限制英偉達、AMD 以及更多更先進 AI 芯片和半導體設備向中國銷售,此次新規中,BIS 刪除和修訂了部分關于美國、中國澳門等地對華銷售半導體産品的限制措施,包括中國澳門和 D:5 國家組將采取“推定拒絕政策”,並且美國對中國出口的 AI 半導體産品將采取“逐案審查”政策規則,包括技術級別、客戶身份、合規計劃等信息全面查驗。
國內算力自立自強是必然趨勢。此前國內對英偉達芯片依賴度較高,2022 年,中國 AI 加速卡市場中,英偉達占據 85%的出貨量,而國産芯片中,華爲、百度昆侖、寒武紀、燧原各自占比 10%、2%、1%、1%。IDC數據顯示,2023 年上半年,中國加速芯片的市場規模超過 50 萬張。從技術角度看,GPU 卡占有 90%的市場份額,從品牌角度看,中國本土 AI 芯片品牌出貨超過 5 萬張,占比整個市場 10%左右的份額。當前禁運持續升級,但是國內人工智能發展的趨勢和力度並不會因此而發生變化,相反我們更需要重視人工智能的發展,美國對于中國先進芯片的限制升級可能將進一步推動我國高水平科技自立自強的步伐。
預計未來國産化比例將大幅提升,短期由于國內算力芯片供需的缺口,包括 H20 等在內的海外芯片也預計對國內算力行業進一步形成補充。H20 芯片在單卡性能上不具備突出優勢,但利用 NVLINK 技術集群性能提升。

2.3 當前國産芯片性能或已接近 A100,或優于 H20
目前華爲海思、寒武紀、平頭哥、壁仞科技、百度昆侖芯、燧原科技、海光等國內 GPU 廠商均已推出用于訓練、推理場景的算力芯片,並且持續叠代升級,性能在不斷提升。而生態方面,國內 GPU 廠商也推出軟件開發包,支持 TensorFlow、Pytorch 等主流框架,並且基于自身的軟件建立了開發平台,吸引更多的開發者建立完善生態體系。
國産頭部芯片單芯片算力或已接近 A100,或優于 H20。以 FP16 精度爲例,國産芯片中華爲昇騰 910 算力爲 256TFLOPS,略低于 A100 的 312TFLOPS,相較于 H100 的 1513TFLOPS 有較大差距,但強于 H20 的148TFLOPS。此外,平頭哥含光 800 在 INT8 精度,壁仞科技 BR100 在 FP32 精度均超過 A100。在單顆芯片峰值算力上,國産芯片已經滿足大規模使用條件。隨著國産芯片能力的提升,國內算力産業發展將進一步提速。

三、國産算力産業鏈環節梳理
3.1 服務器:AI 高增,國産算力芯片發展或帶來格局生變
通用服務器相對疲軟,AI 服務器高增。受經濟持續疲軟、高通脹、企業資本支出縮減、去庫存等影響,2023年服務器市場整體出貨量不及預期。IDC 數據顯示,2023 年第三季度,全球服務器銷售額爲 315.6 億美元,同比增長 0.5%;出貨量爲 306.6 萬台,同比下降 22.8%;預計 2023 年全球服務器市場規模微幅增長至 1284.71 億美元,增長率 4.26%;預計未來四年的年增長率預計分別爲 11.8%、10.2%、9.7%和 8.9%。到 2027 年,市場規模預計將達到 1891.39 億美元。Trendforce 數據顯示,預計 2023 年中國服務器需求將同比下降 9.7%。通用服務器受 AI 需求暴漲、全球整機支出向 AI 傾斜影響,通用服務器市場被進一步壓縮。IDC 數據,2023 年上半年全球通用服務器市場和 CPU 市場規模均出現下滑,其中二季度 CPU 市場同比下滑 13.4%。AI 服務器高增。IDC預計,全球人工智能硬件市場(服務器)規模將從 2022 年的 195 億美元增長到 2026 年的 347 億美元,年複合增長率達 17.3%。IDC 預計,2023 年中國人工智能服務器市場規模將達到 91 億美元,同比增長 82.5%,2027年將達到 134 億美元,五年年複合增長率達 21.8%。

AI 服務器占比提升和國産化率提升,國內服務器廠商競爭格局或存變數。此前服務器競爭格局中,浪潮、新華三等廠商份額較高。2022 年中國服務器市場份額來看,浪潮、新華三、超聚變、甯暢、中興位列前五,份額分別爲 28%、17%、10%、6%、5%。2022 年我國 AI 服務器市場份額來看,浪潮、新華三、甯暢、安擎、坤前、華爲位列前六,份額分別爲 47%、11%、9%、7%、6%、6%。隨著國産 AI 芯片占比的提升,AI 服務器供應商格局或存在變化。當前昇騰在國産 GPU 中性能較爲領先,國內深度參與華爲昇騰算力服務器供應的廠商有望更爲受益,具體可參考中國電信、中國移動等中標候選人情況。未來隨著國內其他廠商 GPU 新産品的推出以及推理等場景的豐富,國內 GPU 生態也有望更加豐富,進一步可能存在新的變化。
國産化的大趨勢下,通用服務器市場格局或同樣産生變化。國産化 CPU 服務器中,X86 解決方案目前有海光、兆芯、瀾起,並以海光爲主;ARM 解決方案有華爲鲲鵬、飛騰等。中國移動 2021-2022 年 PC 服務器集采中,采用海光芯片的服務器 59982 台占比 20.90%,采用鲲鵬芯片的服務器 58901 台,占比 20.53%,合計整體國産服務器占比高達 41.43%。近期中國移動 2024 年 PC 服務器産品集采項目中,ARM 服務器對比 X86 服務器的招投標數量達 1.71:1,ARM 服務器份額超越 X86。





3.2 交換機:以太網高速産品逐步成熟,高端産品預計實現快速增長
AI 部署需要更大的網絡容量,數據中心交換帶寬當前處于每兩年翻一番的速度快速增長。2022 年 8 月,博通發布 Tomahawk 5,交換帶寬提升至 51.2T,serdes 速率達到 100Gb/sec,單通道速率最高達到 800G,可以支持 800G、1.6T 網絡部署。下一代交換機帶寬將向 102.4T 升級,進一步爲 1.6T、3.2T 網絡奠定基礎。
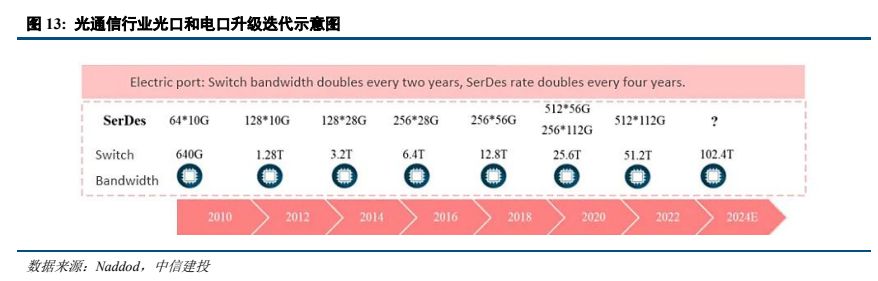
受益于 AI 發展的帶動,高端交換機需求快速增長。根據 IDC 數據,2023 年全球以太網交換機收入達到 442億美元,同比增長 20.1%,其中數據中心部分的市場收入同比增長 13.6%,占整個市場收入的 41.5%,2023 年全年,數據中心部分 200/400 GbE 交換機的收入同比增長 68.9%。工業富聯 2023 年年報顯示,800G 高速交換機已進行 NPI,預計 2024 年將開始上量並貢獻營業收入,預計 2024 年將是 800 Gbps 端口部署的重要一年,預計到 2027 年 400 Gbps/800 Gbps 的端口數量滲透率將達到 40%以上。國內由于政企等需求較弱、高端 AI 算力芯片供應短缺等影響,IDC 數據,2023 年中國以太網交換機收入同比下降 4%(2022 年規模近 50 億美元),但2023 年四季度同比增長了 9.1%,隨著國內算力建設,預計國內高端交換機滲透提升將加速,拉動整體需求。

Infiniband 當前份額提升。AI 高性能計算場景對于網絡性能要求進一步提升。InfiniBand 最重要的一個特點是采用 RDMA 協議(遠程直接內存訪問),從而實現低時延。相較于傳統 TCP/IP 網絡協議, RDMA 可以讓應用與網卡之間直接進行數據讀寫,無需操作系統內核的介入,從而使得數據傳輸時延顯著降低。InfiniBand技術以端到端流量控制爲網絡數據包收發的基礎,能夠確保無擁塞發出報文,從而大幅降低規避丟包所導致的網絡性能下降的風險。並且 InfiniBand 引入 SHARP 技術(可擴展分層聚合和歸約協議),使得系統能夠在轉發數據的同時在交換機內進行計算,以降低計算節點間進行數據傳輸的次數,從而大幅提升計算效率。InfiniBand作爲一個用于高性能計算的網絡通信標准,其優勢在于高吞吐和低延遲,可以用于計算機和計算機、計算機和存儲以及存儲之間的高速交換互連,InfiniBand 目前傳輸速度達到 400Gb/s。根據技術發展路線圖,2024 年 IBTA計劃推出 XDR 産品 ,四通道對應速率 800Gb/s,八通道對應速率是 1600Gb/s,並將于 2 年後發布 GDR 産品,四通道速率達 1600Gb/s。當前在 IB 市場上,主要是 Nvidia(收購的 Mellanox 公司)和 Intel(收購的 Qlogic 公司)兩大玩家。得益于更優秀的性能以及英偉達的一體化銷售戰略,目前 Infiniband 在 AI 市場處于領先地位。
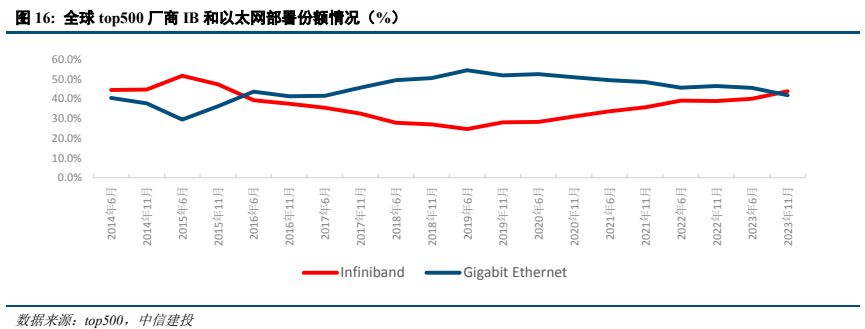
以太網也持續提升性能支撐高性能計算場景。以太網也有相關 RDMA 技術標准,尤其是 RoCE(RDMA over Converged Ethernet)的出現和成熟,RDMA 在基于以太網的數據中心得到規模應用。IBTA 在 2010 年發布了RoCE 協議技術標准,在 2014 年發布了 RoCEv2 協議技術標准,經過多年的發展,RoCE 已經具備路由能力,且在性能表現提升明顯。2022 年 11 月,Broadcom 和 Arista 宣布了針對基于融合以太網 (RoCE) 的遠程直接內存訪問(RDMA)優化的開放式端到端網絡解決方案。2023 年 5 月,英偉達推出 NVIDIA Spectrum-X,交換帶寬 51.2T,通過 RoCE 擴展提升 NVIDIA 集體通信庫性能。但 RDMA 原本設計用于連接較小規模的節點,其設計本身是爲了高性能低延時,這使得它對網絡有很高的要求,特別是網絡不能丟包,否則性能下降會很大,這對底層網絡硬件提出了更大的挑戰,同時也限制了 RDMA 的網絡規模。另外 RDMA 通過硬件實現高帶寬低時延,對 CPU 的負載很小,硬件的使用和管理較爲複雜。面對 AI 高性能計算場景,全球成立超以太網聯盟 UEC、中國移動推動全調度以太網 GSE,進一步提升以太網傳輸性能。2023 年 7 月,硬件設備廠商博通、AMD、思科、英特爾、Arista、Eviden、HP 和超大規模雲廠商 Meta、微軟共同創立 UEC(Ultra Ethernet Consortium,超以太網聯盟),在物理層、鏈路層、傳輸層和軟件方面致力于開發開放的“Ultra Ethernet”解決方案,打造高性能以太網,以新形式進行傳輸層處理,在非無損網絡的情況下也可實現以太網性能提升,較 RDMA 更靈活。
2023 年 8 月,中國移動研究院攜手 30 余家合作夥伴啓動“全調度以太網(GSE)推進計劃”,基于逐包的以太網轉發和全局調度機制,突破傳統無損以太性能瓶頸,2023 年 9 月,中國移動研究院攜手合作夥伴發布業界首款“全調度以太網(GSE)”樣機。綜合來看,以太網支撐高性能計算場景已經逐步得到驗證。

CPO、硅光等技術將在高端交換機中使用。共封裝光學(CPO)是業界公認的未來更高速率光通信的主流産品形態之一,可顯著降低交換機的功耗和成本。隨著交換機帶寬從最初的 640G 升級到 51.2T,Serdes 速率不斷升級疊加數量的持續增加,交換機總功耗大幅提升約 22 倍,而 CPO 技術能夠有效降低 Serdes 的功耗,因此在 51.2T 及以上帶寬交換機時代,CPO 有望實現突破。硅光芯片是 CPO 交換機中光引擎的最佳産品形態,有望在未來得到廣泛應用。海外博通、英特爾、Meta 等廠商在 CPO 交換機産品均有布局。新華三 2023 年 6 月首發51.2T 800G CPO 硅光數據中心交換機,融合 CPO 硅光技術、液冷散熱設計、智能無損等技術,滿足智算網絡對高吞吐、低時延、綠色節能的需求,其基于數據中心 RoCE 全業務場景的解決方案也已經逐步商用落地。銳捷網絡也已經推出 51.2T 硅光 NPO 交換機和 25.6T 硅光 NPO 交換機等産品。

國內 AI 服務器部署規模的增加、國內 GPU 芯片的持續叠代、以太網高速交換機方案的成熟,將利好國內交換機廠商參與國內算力建設,國內交換機廠商 400G、800G 相關訂單預計將實現高速增長。交換機具備技術壁壘,國內廠商已推出高端産品應對 AI 需求。全球來看,全球以太網交換機領域,思科份額第一,此外 Arista、華爲、HPE 等份額居前。國內市場來看,參考 IDC 數據,2023 年一季度,新華三(34.5%)、華爲(30.9%)、銳捷(14.9%)位列國內前三。目前國內多家交換機廠商均推出了 51.2T 交換機,銳捷在 2022 年 3 月推出了 51.2T硅光 NPO 冷板式液冷交換機,新華三在 2023 年 6 月推出了 51.2T 800G CPO 硅光數據中心交換機(H3C S9827系列),浪潮在 2023 年 11 月推出了旗艦級 51.2T 高性能交換機(SC8670EL-128QH)。
互聯網廠商加大自研,或引起格局新的變化。阿裏、騰訊、字節在 2023 年均發布了自研的 51.2T 白盒交換機並宣布規模商用,分別是阿裏的“白虎”、騰訊的 TCS9500 和字節跳動的 B5020。互聯網廠商的強勢入局或帶來市場份額新的變化。

以太網交換設備由以太網交換芯片、CPU、PHY、PCB、接口/端口子系統等組成,高速交換機需求也將直接拉動高速交換芯片需求。全球以太網交換芯片主要以博通、美滿、高通、華爲、瑞昱、英偉達、英特爾等廠商爲主,其中思科、華爲以自用芯片爲主。國內交換機市場以博通、美滿、瑞昱、華爲、盛科通信等廠商參與爲主,參考盛科通信招股書,2020 年中國商用以太網交換芯片市場以銷售額口徑統計,份額排名前三的供應商合計占據了 97.8%的市場份額,其中博通、美滿和瑞昱分別以 61.7%、20.0%和 16.1%的市占率排名前三位,盛科通信的銷售額排名第四,占據 1.6%的市場份額。國內廠商在高速交換芯片領域與海外仍有差距,國産化趨勢下,國內廠商也正在加速追趕,盛科通信在招股說明書中提到,公司擬于 2024 年推出 Arctic 系列,交換容量最高達到 25.6Tbps,支持最大端口速率 800G,面向超大規模數據中心,交換容量基本達到頭部競爭對手水平。

--- 報告摘錄結束 更多內容請閱讀報告原文 ---
報告合集專題一覽 X 由【報告派】定期整理更新
(特別說明:本文來源于公開資料,摘錄內容僅供參考,不構成任何投資建議,如需使用請參閱報告原文。)
精選報告來源:報告派科技 / 電子 / 半導體 /
人工智能 | Ai産業 | Ai芯片 | 智能家居 | 智能音箱 | 智能語音 | 智能家電 | 智能照明 | 智能馬桶 | 智能終端 | 智能門鎖 | 智能手機 | 可穿戴設備 |半導體 | 芯片産業 | 第三代半導體 | 藍牙 | 晶圓 | 功率半導體 | 5G | GA射頻 | IGBT | SIC GA | SIC GAN | 分立器件 | 化合物 | 晶圓 | 封裝封測 | 顯示器 | LED | OLED | LED封裝 | LED芯片 | LED照明 | 柔性折疊屏 | 電子元器件 | 光電子 | 消費電子 | 電子FPC | 電路板 | 集成電路 | 元宇宙 | 區塊鏈 | NFT數字藏品 | 虛擬貨幣 | 比特幣 | 數字貨幣 | 資産管理 | 保險行業 | 保險科技 | 財産保險 |

